지난 글
갈아먹는 추천 알고리즘 [2] Collaborative Filtering
갈아먹는 추천 알고리즘 [3] Matrix Factorization
갈아먹는 추천 알고리즘 [4] Alternating Least Squares
들어가며
이 전 글에서 Alternating Least Squares 알고리즘의 개념과 수학적 원리를 알아보았습니다.
이번 글에서는 직접 스텝 바이 스텝으로 구현해보면서 실제 코드로 수식이 어떻게 표현되는가를 알아보겠습니다.
그리고 실제로 ALS 알고리즘으로 Latent Factor를 학습시킬 수 있는지 눈으로 확인해보겠습니다.
주피터 노트북과 파이썬 파일 두 가지 버전으로 구현을 진행하였고, 저장소는 다음과 같습니다. (스타 한번씩 부탁드려요ㅎㅎ)
이번 글에서는 주피터 노트북으로 작성한 구현을 중심으로 설명드리겠습니다.
https://github.com/yeomko22/ALS_implementation
yeomko22/ALS_implementation
Implementation of ALS algorithm from "Collaborative Filtering for Implicit Feedback Data" - yeomko22/ALS_implementation
github.com
1. 학습 파라미터 초기화
초기화시키는 변수들은 정규화에 필요한 lambda, confidenc level 조정에 필요한 alpha
그리고 사용자와 아이템의 Latent Factor 행렬의 차원 nf 입니다.
해당 논문에서 가장 좋은 결과를 냈다고 나온 값인 40, 200, 40으로 초기화를 시켰습니다.

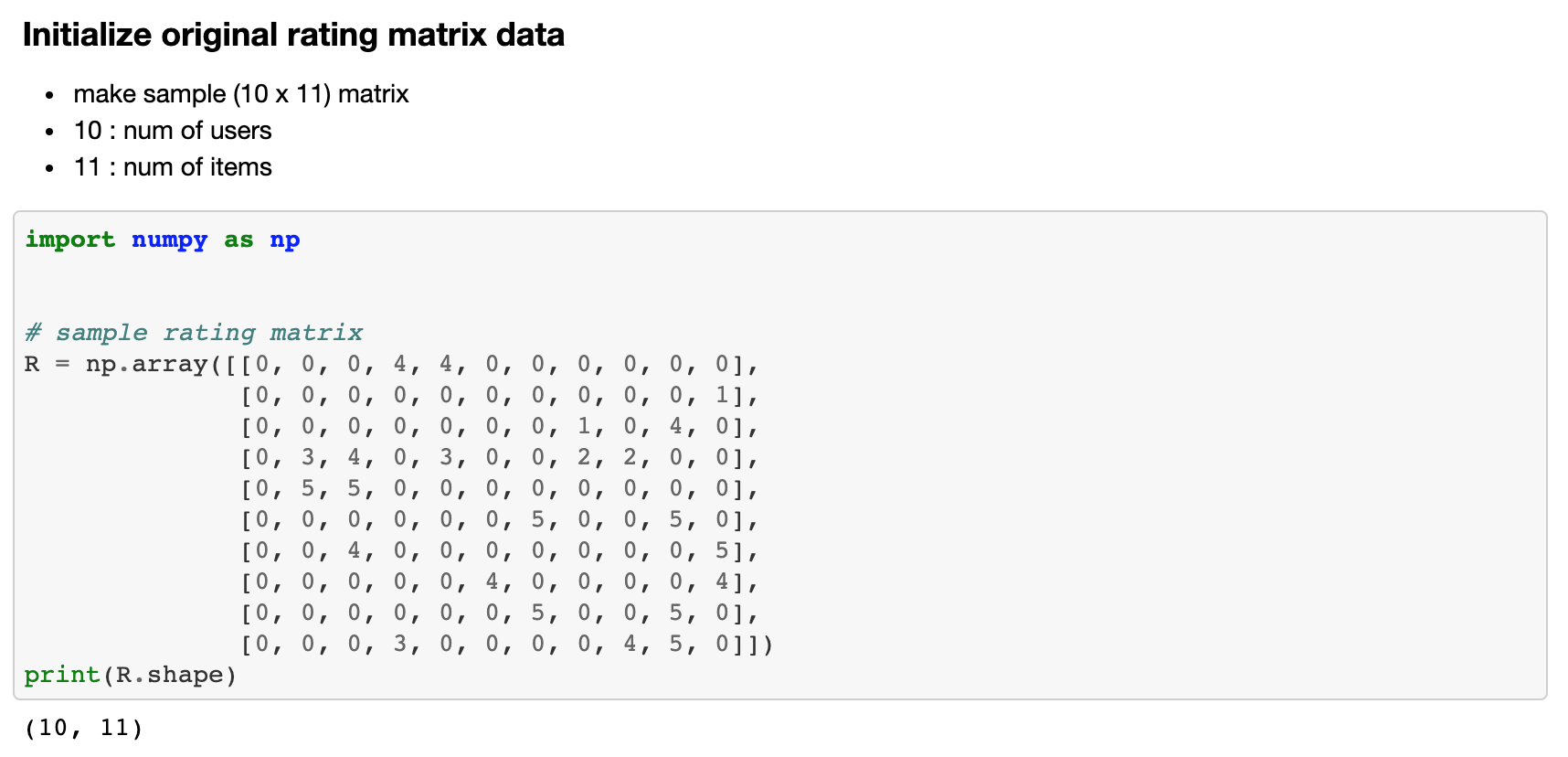
2. 학습용 평점 데이터 설정
다음으로 학습시킬 평점 데이터 행렬을 생성합니다.
여기서는 임의의 10 x 11평점 행렬을 numpy 라이브러리를 통해서 생성합니다.
이 때 10은 사용자의 수, 11은 아이템의 수가 됩니다.
3. 사용자와 아이템의 Latent Factor Matrix를 초기화
아주 작은 랜덤한 값들로 행렬의 값들로 초기화시킵니다.

4. 선호도 행렬 P 설정
다음으로 주어진 학습용 평점 테이블을 0과 1로 된 binary rating matrix P로 바꾸어줍니다.
P를 구하는 공식과 실제 코드 구현은 다음과 같습니다.
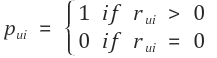

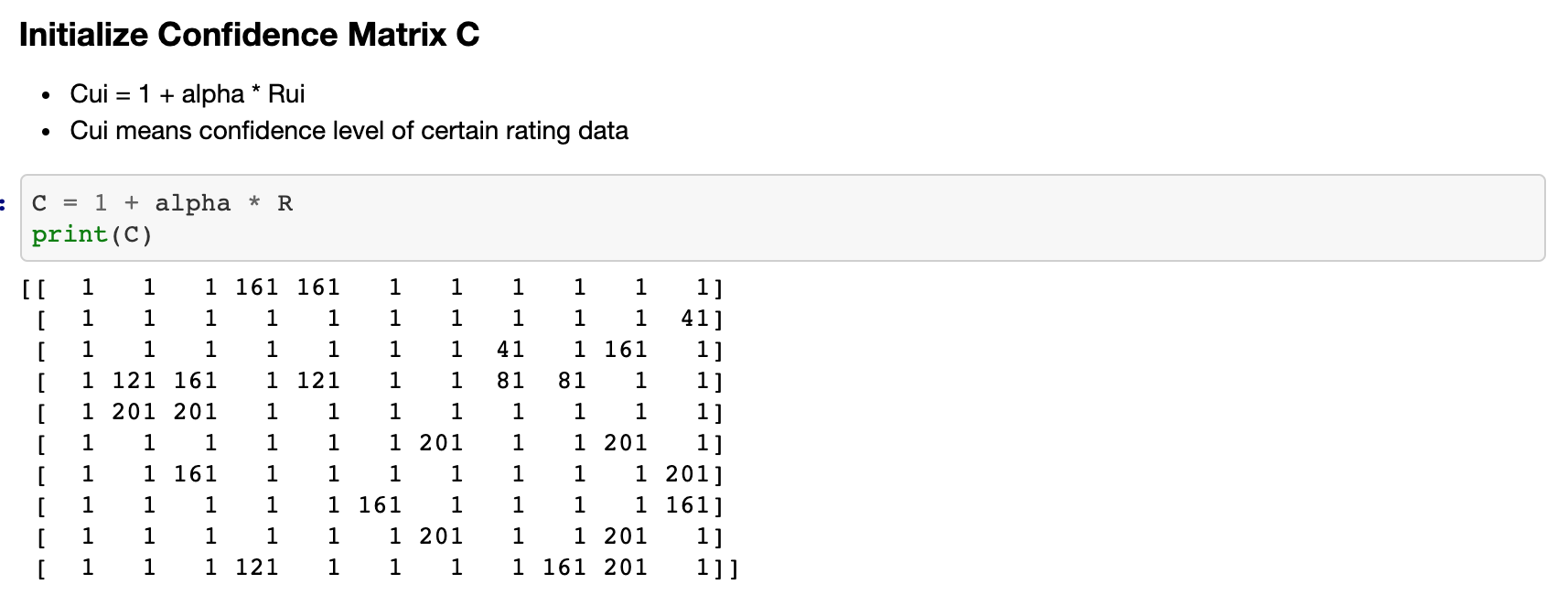
5. 신뢰도 행렬 C 설정
다음으로 주어진 학습용 평점 테이블에 Confidence level을 적용한 C 행렬을 구합니다.
confidence level을 구하는 공식과 실제 코드 구현은 다음과 같습니다.

6. Loss Function 설정
이제 예측이 얼마나 정확한 지를 측정할 Loss Function을 작성합니다.
Loss Function의 공식은 다음과 같습니다.
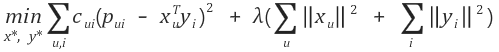
Loss Function을 크게 네 가지 부분으로 나누어서 train 시에 변화 추이를 지켜볼 예정입니다.
predict error : (pui - xTyi) ^ 2 (0과 1로 나누어 선호 비선호를 예측한 결과의 에러)
confidence error: cui(pui - xTyi) ^ 2 (confidence level을 적용한 predict error)
regularization: lambda(sumX +sumY) (정규화를 위한 값)
total loss: confidence error + regularization (최종 loss)

7. Optimizer 설정
로스 펑션을 구했으니, 이를 최적화 시키는 Optimizer를 작성합니다.
이 부분이 ALS 알고리즘의 핵심적인 부분입니다.



8. 학습
모든 준비가 완료되었습니다. 이제 드디어 학습을 진행할 수 있습니다.
학습은 보통 10 ~ 15회 정도 진행합니다.
각 스텝별로 로스 펑션을 출력하도록 구현하였습니다.
그리고 학습이 완료되면 최종 선호도 (0 or 1) 예측을 출력합니다.

9. 학습 결과 분석 및 시각화
학습을 진행하면서 출력되는 결과는 다음과 같습니다.

이를 시각화하면 다음과 같습니다.

Predict Error의 경우 처음엔 증가하지만, 이내 감소하여 안정적으로 수렴합니다.
Confidence Error와 Total Loss는 안정적으로 감소하는 모습을 보입니다.
최종 Loss가 일정 수준 이하로 떨어지지 않는 이유는
바로 평점 데이터에서 0으로 주어진 항목들에 대한 예측 값을 반환하기 때문입니다.
이는 Loss Function에서는 에러라고 간주하기 때문에 Total Loss가 일정 수준 이하로 떨어지지 않습니다.
Regularization의 경우 처음엔 작은 값이다가 급격하게 증가하여 일정하게 유지되는 것을 볼 수 있습니다.
초반에 작은 값을 가지는 것은 사용자와 아이템의 Latent Matrix를 아주 작은 값들로 초기화를 하였기 때문입니다.
하지만 학습이 진행되면서 Latent Matrix가 어느 정도 값을 가지게 되면
regulaization의 크기가 커지면서 일정 수준을 유지하게 됩니다.
최종 예측 결과와 학습용 데이터를 비교하면 다음과 같습니다.
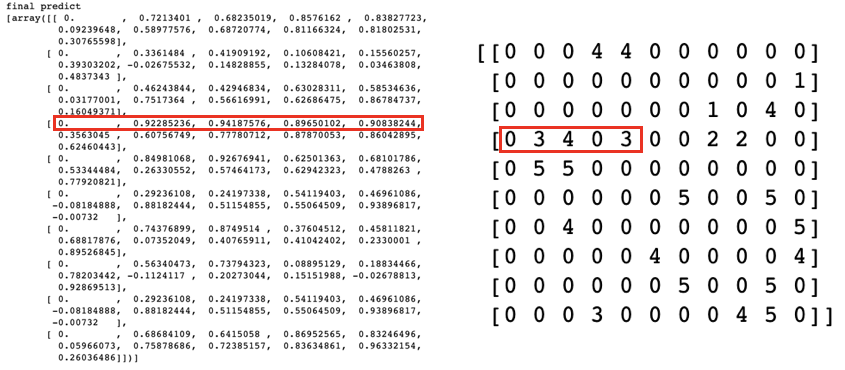
최종 예측 결과를 분석해보면 원본 평점이 높을 수록 더 높은 값을 예측합니다.
붉은 색 네모로 표시한 부분을 보면 원본 평점에서 3과 4를 기록한 항목에 대해서 각각 0.92, 0.94로 높은 선호도를 예측합니다.
네 번째 항목의 경우 원본 평점 행렬에서는 0이었지만 높은 예측 값을 갖는 것을 확인할 수 있습니다.
이러한 항목들이 곧 추천 결과물로 제공되게 됩니다.
한편 첫 번째 항목의 경우 여전히 예측값이 0으로 남아있는 모습을 볼 수 있습니다.
이는 원본 평점 행렬에서 첫 번째 열에 해당하는 값들이 모두 0으로 남아있기 때문입니다.
즉, 아무도 평점을 내려주지 않은 아이템에 대해서는 선호도를 예측할 수 없는 cold start 문제를 의미합니다. (ex. 신작 영화)
마치며
지금까지 추천이란 키워드로 Collaborative Filtering, Matrix Factorization, ALS의 개념을 살펴보았습니다.
그리고 실제 구현을 통해서 ALS가 실제 어떻게 작동하는 지를 확인하였습니다.
이상으로 갈아먹는 머신러닝 추천 알고리즘 편을 마무리 지어볼까 합니다.
물론 ALS 알고리즘을 Parallel하게 돌릴 수 있는 원리, Baysian Personalized Ranking 등
아직 다루지 못한 심화 주제들이 많이 있습니다.
하지만 특히 머신러닝 분야가 그렇듯 파고들면 끝이 없을것 같더라구요 ㅎㅎ
누군가에게 도움이 되었길 바라면서 이만 마치겠습니다.
Reference
[1] Y. Hu et al, Collaborative Filtering for Implicit Feedback Datasets
[2] Kevin Liao, Prototyping Recommendation System, Medium, https://towardsdatascience.com/prototyping-a-recommender-system-step-by-step-part-2-alternating-least-square-als-matrix-4a76c58714a1
'갈아먹는 머신러닝 시리즈 > 추천 알고리즘' 카테고리의 다른 글
| 👇 갈아먹는 추천 알고리즘 (0) | 2023.10.26 |
|---|---|
| 갈아먹는 추천 알고리즘[6] 추천 엔진 성능 지표 (5) | 2020.04.18 |
| 갈아먹는 추천 알고리즘 [4] Alternating Least Squares (13) | 2019.03.21 |
| 갈아먹는 추천 알고리즘 [3] Matrix Factorization (8) | 2019.03.21 |
| 갈아먹는 추천 알고리즘 [2] Collaborative Filtering (6) | 2019.03.21 |