지난 글
갈아먹는 추천 알고리즘 [2] Collaborative Filtering
갈아먹는 추천 알고리즘 [3] Matrix Factorization
갈아먹는 추천 알고리즘 [4] Alternating Least Squares
들어가며

오랜만에 추천 알고리즘에 관련된 내용을 포스팅 해봅니다. 바로 추천 엔진의 성능은 어떻게 평가할 것인가 입니다. 클래시피케이션 모델의 경우에는 accuracy, precision, recall, f1-score 등의 지표가 있고 object detection의 경우에는 mAP, 리그레션 모델 같은 경우에는 r2-score 등의 지표들이 있습니다. 이러한 성능 평가 지표들을 우리는 metrics라고 부릅니다. 그렇다면 추천 엔진의 성능은 어떠한 메트릭들로 평가 할 수 있을까요?
추천 엔진의 특성
추천 엔진의 정확도를 평가하기 위해서는 먼저 다음 두 가지 요소를 고려해야합니다.
1. 순서(Ranking)
하나는 추천의 결과물들의 순서입니다. 유투브 앱을 켜보면 내가 좋아할만한 영상부터 상단에 노출됩니다. 추천 엔진이 사용자의 신뢰를 받기 위해서는 사용자가 좋아할 만한, 실제로 소비할 만한 아이템을 가장 상단에 배치하는 것이 중요합니다. 따라서 추천 엔진의 성능 평가 지표는 이러한 순서 정보를 반영할 수 있어야합니다.
2. 개인화(Personalization)
다음으로 얼만큼 다양하게 추천을 해주었는지입니다. 모든 사용자들에게 동일한 추천 결과물을 제공해준다면 개인화 추천이라 보기 어렵겠죠? 성능이 높은 추천 엔진이라면 개개인의 취향에 맞춘 아이템들을 추천할 것입니다.
추천 도메인에서는 이러한 특징들을 고려하여 하나의 메트릭으로만 평가하지 않고 mAP, NDCG, Entropy Diversity 세 가지 지표를 통해서 성능을 평가합니다.
mAP(Mean Average Precision)
mean average precision은 recall의 값이 0부터 1까지 변화할 때 precision 값의 평균 값입니다. recall과 precision에 대해서 헷갈리신다면 먼저 다음 자료를 살펴보시면 됩니다.[1] 예시를 통해서 mAP의 개념을 익혀보겠습니다.

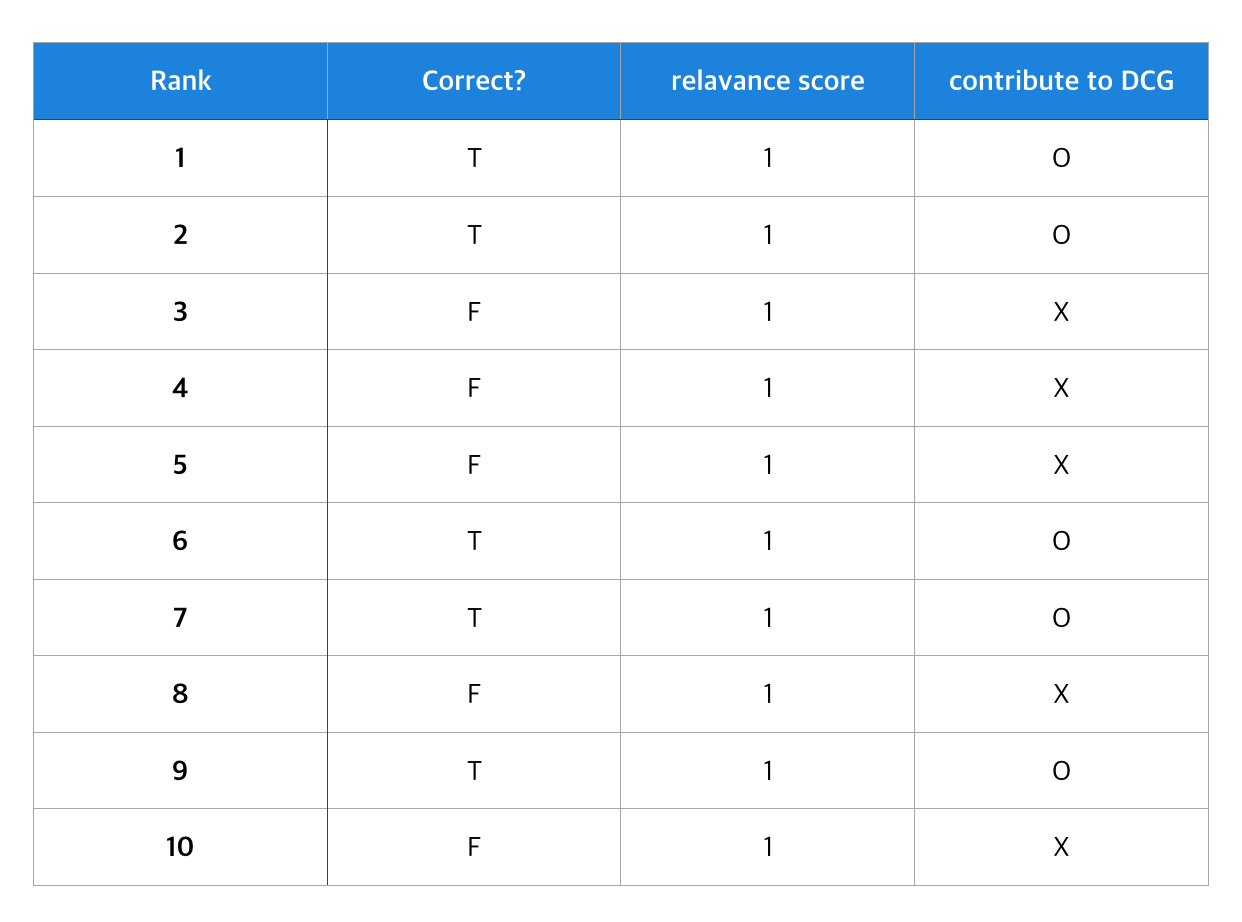
10개의 아이템을 추천하였고(RANK 1~10) 사용자가 실제로 소비하였는 지 여부를 Correct로 표시하였습니다. Rank가 낮을 수록 유저에게 우선적으로 추천되는 아이템입니다. 그리고 사용자가 실제로 소비한 전체 아이템은 5개라고 가정하겠습니다.
위 사례에서 mAP는 (1.0 + 1.0 + 0.66 + 0.5 + 0.4 + 0.5+ 0.57 + 0.5+ 0.55) / 9 = 0.63이 됩니다. 9에서 이미 recall이 0이 되었기 때문에 10번째 값은 고려하지 않습니다. 만일 똑같이 10개를 추천했는데 첫 번째 값을 틀리고 열 번째 값을 맞추면 어떻게 될까요?

(0.0 + 0.5 + 0.33 + 0.25 + -.2 + 0.33 + 0.42 + 0.375 + 0.44 + 0.5) / 10 = 0.3345가 됩니다. 단지 정답을 맞춘 순서만 달라졌음에도 mAP가 두 배 가까이 차이가 나는 것을 확인할 수 있습니다. 이렇게 순서 정보를 반영하여 정확도를 평가할 수 있어서 추천 엔진의 성능을 평가할 때에 사용됩니다.
하지만 사용자에 따라서 실제로 소비한 아이템의 수가 천 개, 2천개까지 늘어날 수 있습니다. 이 경우 recall이 1이 되는 지점까지 고려하는 것은 무리이므로 최대 n개까지만 고려하여 mAP를 계산하며, 이 경우 mAP@n 으로 표기합니다. 만일 mAP example 1의 mAP@5를 구한다면 (1.0 + 1.0 + 0.66 + 0.5 + 0.4) / 5 = 0.712가 됩니다.
nDCG(normalized Discounted Cumulative Gain)
nDCG는 추천의 순서에 더 가중치를 두어서 성능을 평가하는 지표이며, 1에 가까울 수록 좋습니다. nDCG를 이해하기 위해서 자주 사용되는 예시를 먼저 살펴보겠습니다.[3] 그리고 앞서 살펴본 예시에서는 NDCG를 어떻게 구할 수 있는지 적용해보겠습니다.
추천 엔진은 기본적으로 각 아이템에 대해서 사용자가 얼마나 선호할 지를 평가하며, 이 스코어 값을 relevance score라고 부릅니다. 그리고 이 relevance score 값들의 총 합을 Cumulative Gain(CG)라고 부릅니다.

사용자가 소비한 다섯개의 아이템이 있으며, 먼저 위치한 순서대로 우선순위가 높습니다. 각기 다른 모델 A와 B를 통해서 각 아이템 별로 relavance score가 주어졌다고 했을 때, CG를 구하면 다음과 같습니다.

먼저 위치한 아이템일 수록 중요도가 높으니 model B가 model A보다 성능이 뛰어납니다. 하지만 이 둘의 CG는 동일하므로 CG로는 성능 평가를 할 수 없습니다. 그래서 먼저 위치한 relavance score가 CG에 더 많은 영향을 줄 수 있도록 할인의 개념을 도입한 것이 Discounted Cumulative Gain(DCG)입니다.

model A와 model B의 DCG를 구해보면 다음과 같습니다.
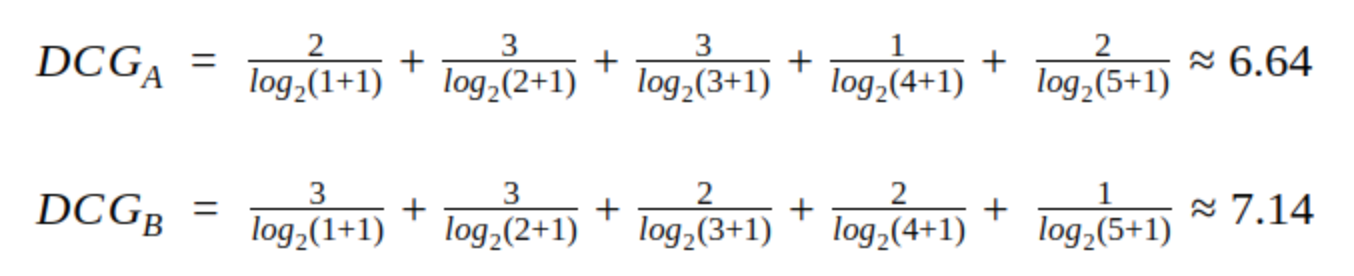
이제 model B가 model A보다 우수하다는 성능 평가를 진행할 수 있습니다. 그런데 여기서 또다시 문제가 발생합니다. 사용자에 따라서 추천 받는 아이템의 개수가 달라질 수 있습니다. 예를들어 하루에 100개의 동영상을 소비하는 사용자와 10개의 동영상을 소비하는 사용자에게 제공되는 추천 아이템의 개수는 다를 수 밖에 없습니다. 이 경우 추천 아이템의 개수를 딱 정해놓고 DCG를 구하여 비교할 경우 제대로 된 성능 평가를 진행할 수 없습니다. 때문에 DCG에 정규화를 적용한 NDCG(normalized discounted cumulative gain)이 제안됩니다.
NDCG를 구하기 위해서는 먼저 DCG와 함께 추가적으로 iDCG를 구해주어야 합니다. iDCG의 i는 ideal을 의미하며 가장 이상적으로 relavace score를 구한 것을 말합니다. NDCG는 DCG를 iDCG로 나누어 준 값으로 0에서 1 사이의 값을 가지게 됩니다.

이제 다시 mAP example1의 사례로 돌아와봅시다. 방금 살펴본 사례와 다른 점은 relavance score가 없이 True or False만으로 표기된다는 것입니다. 추천으로 제공된 동영상들 가운데 사용자가 본 동영상과 보지 않은 동영상과 같이 바이너리하게 주어진 데이터를 가지고 추천 엔진의 성능을 평가해야한다면 어떻게 해야할까요?
우선 relavance score는 아이템의 순서와 상관없이 1로 놓습니다. 그리고 사용자가 실제로 소비한 아이템의 relavance score만 합산하여 DCG를 구해줍니다. iDCG의 경우 사용자가 소비한 아이템의 개수, 혹은 mAP에서 처럼 최대 n개까지만 relavance score를 1로 놓고 iDCG를 구해주며, 이 둘을 나눠주어 NDCG를 구합니다.

Entropy Diversity
지금까지 추천 알고리즘이 얼마나 정확하게 정답을 맞추었는지를 순서에 가중치를 두어 계산하는 mAP와 NDCG를 알아보았습니다. 그런데 아직 전체 아이템에서 얼마나 다양하게 추천을 진행했는지는 평가하지 못했습니다. Entropy Diversity는 추천 결과가 얼마나 분산 되어 있느냐를 평가하는 지표입니다.
Entropy Diversity를 이해하기 위해서는 먼저 Entropy를 이해할 필요가 있습니다. 이는 섀넌의 정보 이론에서 제안된 개념으로 우리가 딥 러닝에서 Classification 문제를 풀 때 loss로 사용하여 친숙한 Cross Entropy 역시 이 Entropy의 한 종류입니다. 정보 이론과 Entropy에 대해서 더 알고 싶으신 분들은 다음의 자료를 참고하시면 됩니다.[4]
Entropy는 섀넌의 정보 이론에서 등장한 개념으로 머신러닝에서도 많이 사용됩니다. 간략하게 설명하면 잘 일어나지 않는 사건의 정보량은 잘 일어나는 사건의 정보량보다 많다는 것입니다. 이를 사건이 일어날 확률에 로그를 씌워서 정보량을 표현하며 로그의 밑의 경우 자연 상수를 취해줍니다. (다른 상수도 가능하긴 합니다.)
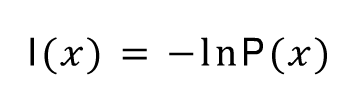

예를 들어 윷놀이에서 개가 나올 확률은 6/16입닌다. 이를 정보량으로 계산해보면 -ln(6/16) = 0.98이 나옵니다. 반면 윷이 나올 확률은 1/16이며 -ln(1/16)은 2.77입니다. 발생할 확률이 낮은 윷이 정보량이 더 낮은 것을 볼 수 있습니다. 엔드로피란 발생할 수 있는 모든 사건들의 정보량의 기대 값입니다. 수식으로 표현하면 아래와 같습니다.

그렇다면 윷놀이의 엔트로피를 계산해보면 최종적으로 1.40875를 얻게 됩니다.

Entropy Diversity란 이러한 엔트로피의 개념을 추천 결과에 적용한 것입니다. 모든 사용자들에게 비슷한 종류의 상품을 추천할 경우 해당 상품 추천은 자주 발생하므로 정보량이 낮습니다. 반면 개인에게 맞춤화 된 추천은 발생 횟수가 적으므로 정보량이 높아집니다. 이들의 기대값을 구한 것이 바로 Entropy Diversity입니다.

5명의 유저에게 A부터 다섯개의 아이템 가운데 한개를 추천해주는 model A와 model B가 있다고 가정하겠습니다. model A는 모든 유저에게 상품 A를 추천하였습니다. 이 경우 A가 추천될 확률은 1, 정보량은 0이 됩니다. 모든 유저대한 추천의 정보량이 0이므로 Entropy Diversity 역시 0이 됩니다. 반면 model B의 경우 모든 유저에게 각기 다른 상품을 추천합니다. 이 때 각각의 상품이 추천되는 확률은 0.2, 정보량은 0.32, 엔트로피는 1.6이 됩니다.

model B가 model A 보다 더 다양한 추천을 제공해주었다고 볼 수 있습니다. 그러나 Entropy Diversity 만으로 추천 엔진이 더 정확하다고 평가할 수 는 없습니다. 어디까지나 추천 결과의 다양성을 측정하는 지표이므로 mAP나 NDCG처럼 정확도를 측정할 수 있는 지표와 함께 사용하는 것이 바람직해 보입니다.
마치며
지금까지 추천 엔진의 성능을 측정할 수 있는 세 가지 지표들에 대해서 알아보았습니다. 캐글 등에서 주최되는 추천 문제 챌린지들은 mAP 단일 지표로 정확도를 측정하거나 mAP, NDCG, Entropy Diversity를 섞어서 사용하는 방식을 취합니다.이 글에서 다루지 못한 다른 많은 지표들도 있으니 더 궁금하신 분들은 다음 논문을 읽어보시길 권합니다.
감사합니다.
[1] https://en.wikipedia.org/wiki/Precision_and_recall
[2] mean average precision, https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
[3] Evaluate your recommendation engine using NDCG, https://towardsdatascience.com/evaluate-your-recommendation-engine-using-ndcg-759a851452d1
[4] 정보이론 기초, https://ratsgo.github.io/statistics/2017/09/22/information/
[5] Improving Aggregate Recommendation Diversity Using Ranking-Based Techniques
'갈아먹는 머신러닝 시리즈 > 추천 알고리즘' 카테고리의 다른 글
| 👇 갈아먹는 추천 알고리즘 (0) | 2023.10.26 |
|---|---|
| 갈아먹는 추천 알고리즘 [5] ALS 구현하기 (7) | 2019.03.29 |
| 갈아먹는 추천 알고리즘 [4] Alternating Least Squares (13) | 2019.03.21 |
| 갈아먹는 추천 알고리즘 [3] Matrix Factorization (8) | 2019.03.21 |
| 갈아먹는 추천 알고리즘 [2] Collaborative Filtering (6) | 2019.03.21 |