들어가며
머신러닝에서 통계학은 뗄레야 뗄 수 없는 관계에 있습니다. 데이터가 어떠한 특성을 가지고 있고, 어떠한 분포를 띄는 지에 따라서 수행해야하는 전처리나 알고리즘이 달라지기도 합니다. 그런 의미에서 통계학의 기초 개념들을 쭉 복습하며 핵심적인 내용들을 정리해보려 합니다.
확률 변수
확률 변수(random variable)은 확률 실험의 결과에 대한 숫자적 표현입니다. 가령 동전을 던진다고 했을 때 앞면을 1, 뒷면을 0이라고 표현한다고 하면 이는 실험 결과의 숫자적 표현이고 확률 변수입니다.[1] 확률 변수는 그것이 취할 수 있는 값들이 한 개, 두개와 같이 셀 수 있으면 이산형 확률 변수(discrete random variable), 셀 수 없을 경우 연속형 확률 변수(continuous random variable)이라 부릅니다. 동전의 경우 나올 수 있는 경우의 수가 앞 면 또는 뒷 면으로 두 가지니까니 이산형 확률 변수입니다. 그러나 같은 반 아이들의 키 처럼 확률 변수가 가질 수 있는 가지 수가 무한한 경우 연속형 확률 변수에 속하게 됩니다.
확률 분포
확률변수가 취할 수 있는 값들에는 확률이 대응되어 있고, 이를 확률 분포(probability distribution)라고 합니다. 더 쉽게 말하면 확률 변수들이 어떠한 형태로 놓여있을까, 어떻게 분포해 있을까를 나타내주는 함수입니다. 확률 분포 역시 확률 변수가 이산형 확률 변수이냐, 연속형 확률 변수이냐에 따라서 이산형 확률 분포, 연속형 확률 분포로 나뉘며, 간단한 예시를 그래프로 표현해보면 아래와 같습니다.

베르누이 분포, 이항 분포
시행의 결과 값이 성공과 실패 두 가지만 가지고, 각 시행의 성공 확률이 p, 실패 확률이 1-p인 실험을 베르누이 시행(Bernoulli trial)이라고 부릅니다. 그리고 이 때의 확률 변수 x는 베르누이 분포를 가진다고 하며 수식으로는 다음과 같이 표기합니다.

이항분포란 n번의 서로 독립적으로 반복된 베르누이 시행 중에서 성공한 횟수를 확률 변수 X라고 놓았을 때, 이 변수 X의 확률 분포를 의미합니다. 윷놀이의 예시를 들어보겠습니다. 윷놀이에서 각각의 작대기(?) 하나를 던지는 것은 앞면 혹은 뒷면의 두 가지 경우의 수를 가지며 앞면이 나올 확률이 1/2인 (아닐 수도 있지만 1/2로 가정하겠습니다.) 베르누이 실행입니다. 그리고 윷을 한번 던지는 행위는 이러한 베르누이 시행을 4번 반복하는 것을 의미합니다. 이제 앞면이 나온 윷의 개수(성공한 시행의 개수)를 확률변수 X로 놓고 확률을 계산해보면 다음과 같습니다.

앞면 하나만 나온 도의 경우를 보겠습니다. 이 경우 네 개의 윳 가운데 하나만 앞면이면 되므로 가능한 윳의 경우는 4가지입니다. 그리고 하나의 윳만 앞면으로 나올 수 있는 확률은 1/2 x 1/2 x 1/2 x 1/2로 1/16입니다. 그러므로 윷을 한번 던졌을 때 도가 나올 확률은 4 x 1/16 = 4/16이며, 이와 같이 각각의 확률 변수의 확률 값을 계산하는 것을 확률 질량 함수라고 합니다.(probability mass function)


이러한 확률 변수 X를 이항 분포를 띈다고 합니다. 이항 분포의 확률 질향 함수를 수식으로 표현하면 아래와 같습니다.
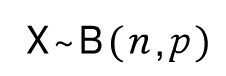
카테고리 분포, 다항 분포
이항 분포의 경우 확률 변수 x가 시행의 결과로 실패 혹은 성공 두 가지 경우의 수 밖에 가지지 못하였습니다. 하지만 주사위의 경우 한번 던졌을 때 나올 수 있는 값이 6개나 됩니다. 이렇게 정수 개의 결과값을 가지는 분포를 카테고리형 분포라고 합니다. 주사위의 경우 K=6인 카테고리 분포를 따른다고 표기할 수 있으며, 이를 수식으로 표현하면 아래와 같습니다. (아래 수식은 윗 수식을 벡터로 줄여서 표현한 것으로 , 두 수식이 의미하는 바는 같습니다.)

확률 질량 함수는 아래처럼 표기할 수 있습니다.


위 수식에서 먼저 각각의 카테고리를 (1, 0, 0, ..., 0), (0, 1, 0, ..., 0) 처럼 one hot encoding을 적용한 것을 볼 수 있습니다. 그리고 각각의 카테고리일 때 확률이 뮤k임을 표시해준 것입니다. 이를 압축해서 표시하면 아래 수식이 되며, ∏ 기호는 파이라고 읽으며 곱셈을 표현해줍니다.
베르누이 시행을 반복하면 이항 분포를 이루는 것처럼 카테고리형 시행을 여러번 반복하면 다항 분포가 됩니다. 예를 들어 주사위를 N번 던진다고 했을 때, 각 면이 나오는 횟수 집합의 분포가 다항 분포입니다. 다항 분포를 수식으로 표현하면 다음과 같습니다.

이항 분포의 수식과 크게 다르지 않습니다만 조합을 계산하는 부분이 차이가 납니다. 주사위의 예로 돌아가보겠습니다. 우리는 주사위를 10번 던졌을 때, 1이 1번, 2가 2번, 3이 1번, 4가2번, 5가 3번, 6이 1번 나오는 확률을 계산하고 싶습니다. 이를 벡터로 나타내면 (1, 2, 1, 2, 3, 1)이 됩니다. 이제 6번을 던졌을 때 x벡터처럼 나올 조합을 계산해야하며, 수식은 아래와 같습니다.

포아송 분포
포아송 분포란 고정된 지역, 시간 또는 부피 등에서 관심 있는 사건의 관찰 수 또는 발생 횟수 X를 표현하는데 사용되는 분포입니다. 예를 들면 하루 동안 서버에 접속한 사용자 수, 어느 주말 일요일에 발생한 교통사고 사망자 수 등이 있습니다. 포아송 분포의 확률 질량 함수와 그래프는 아래와 같습니다. (개인적으로 경영학과 수업에서 큐잉 이론을 배울 때 포아송 분포가 많이 활용되는 것을 보았습니다.)


포아송 분포의 예제가 궁금하신 분들은 다음 자료를 참고하시면 됩니다.[4]
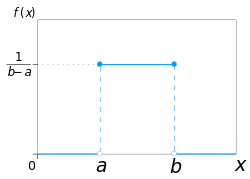
균일 분포(uniform distribution)
확률 변수 X가 어느 구간 (a, b)에서 정의되고, 그 구간에서 확률 밀도 함수가 똑같은 높이의 일정한 확률 분포를 말합니다. U(a,b) 라고도 표기하며 확률 밀도 함수와 그 그래프는 아래와 같습니다.

정규 분포, 가우시안 분포
다음은 평균을 중심으로 좌우가 대칭인 종 모양을 그리는 정규분포입니다. 가우시안 분포라고도 불리며 우리에게 가장 친숙한 확률 분포 가운데 하나입니다. 정규 분포의 확률 밀도 함수와 그 그래프는 아래와 같습니다.


식만 보면 복잡해서 현기증이 나지만 자세히 들여다보면 그다지 어렵지 않습니다. 정규 분포 식에서 변수는 σ와 μ입니다. 그 외에 파이나 자연 지수승 등은 고정되어 있는 값이며 그래프가 종모양의 형태가 되게끔 만들어주는 역할을 합니다. μ는 확률 변수 X의 평균이고 σ는확률 변수 X의 표준 편차입니다. 종 모양의 그래프는 평균을 기준으로 좌우 대칭입니다. 표준 편차가 높을 수록 그래프는 완만한 곡선 형태를 띄게 됩니다.
표준 정규 분포, z-분포
표준 정규 분포는 평균이 0이고 분산이 1인 정규 분포를 말합니다. 이 때의 확률 밀도 함수를 식과 그래프로 표현해보면 아래와 같습니다.


이름에서도 알 수 있듯이 (normal distribution) 현실 세계의 많은 데이터들은 정규분포를 따르고 있습니다. 하지만 각 집단의 평균과 표준 편차가 모두 다르기 때문에 데이터들을 서로 비교하기가 어렵습니다. 예를 들어 A반의 수학 점수가 평균은 70점이고 표준 편자는 30점입니다. 반면 B반은 평균 65점에 표준 편차가 10점이라면 두 반 중 어느 반이 더 수학 점수가 높다고 할 수 있을까요?
이러한 비교를 위헤서 전체 데이터를 평균으로 빼주고, 표준 편차로 나누어 주는 표준화(standardizing) 작업을 거치게 됩니다. 그 결과 두 집단의 수학 점수는 동일하게 표준 정규 분포, z-분포를 따르게 되며 수식으로는 아래 처럼 표현할 수 있습니다. 표준화를 거친 개별 데이터를 우리는 z-score라고 부릅니다.

표준 정규 분포의 중요한 특징 중에 하나는 이를 활용하여 확률 구간을 계산할 수 있다는 것입니다. 평균 0을 기점으로 ±1σ 안에는 전체 데이터의 68.2%가 들어오게 됩니다. 마찬가지로 ±2σ 안에는 전체 데이터의 95.4%, ±3σ 안에는 전체 데이터의 99.7%가 들어옵니다. 더 자세한 내용은 신뢰 구간과 관련된 포스팅에서 다뤄보도록 하겠습니다.
잘린 정규 분포(truncated normal distribution)
truncated distribution이란 확률 변수가 존재할 수 있는 범위에 최대 값 혹은 최소값을 정하여 자른 분포를 의미합니다. 잘린 정규 분포란 이러한 truncated distribution을 정규 분포에 적용한 분포로 수식과 그래프는 아래와 같습니다.


위 그래프를 보시면 정규 분포의 확률 밀도 함수가 -10부터 10 사이에서 범위가 제한되어 있는 모습을 볼 수 있습니다. 이처럼 특정 확률 분포에 범위를 제한하는 것을 truncated distribution이라 부릅니다.
t 분포
t 분포는 정규 분포인 모집단의 모평균을 표본 평균을 통해서 추측할 때 사용되는 분포입니다. 표본 평균을 x̄라 두었을 때 확률 변수 x̄를 정규화 하면 아래와 같은 식이 됩니다. 윗 변에서는 x̄를 x̄의 기대값인 μ로 빼줍니다. 아랫 변에서는 x̄의 표준 편차인 s(n)^1/2로 나누어 줍니다.(표본 평균의 표준편차) 이 때의 s는 표본 표준 편차로 수식은 아래와 같습니다. (이 둘을 구분하는 것이 다소 헷갈립니다.) 구체적인 유도방식이 궁금하신 분들은 [6]과 [7]을 참고하시기 바랍니다.

모집단이 정규 분포일 때 표본 평균의 정규화 식은 정규 분포와 유사한 형태를 갖지만 양 끝단에 데이터가 더 많이 분포하는 형태를 띕니다. 정규 분포를 살펴보았을 때, 표준 편차가 더 클 수록 완만한 종 모양을 띈 다는 것을 살펴보았습니다. 마찬가지로 모집단에서 표본을 추출할 경우 표준 편차가 더 커질 것이라는 것을 예상할 수 있습니다. 이 때문에 곡선의 모양이 더 완만해 지는 것을 t 분포로 설명한다고 이해하면 좋을 것 같습니다.

정규 분포의 경우 그래프의 형태를 표준 편차와 평균이 결정하였습니다. t-분포는 이 둘에 더해 수식 상에서 (n-1)에 해당하는 자유도(degree of freedom)가 그래프의 형태에 영향을 줍니다. 자유도의 정의는 말 그래도 자유스러운 정도로 특정 분포에서 그래프의 모양을 결정하는 모수입니다. 대표적으로 t 분포와 카이제곱 분포가 자유도를 모수로 갖습니다.
표본 평균을 구할 때에는 자유도가 n-1인 t-분포를 적용하였습니다. 왜 n-1이 자유도가 될까요? 예를들어 모집단에서 3개의 표본을 추출하여 표본 평균을 구한 결과 5가 나왔다고 해보겠습니다. 가능한 표본은 (5, 5, 5), (3, 5, 7), (1, 5, 9) 등이 있습니다. 여기서 첫 번째 수와 두번째 수에는 어떤 수를 대입하여도 좋지만 마지막 수만큼은 표본 평균을 5로 맞추기 위한 수가 들어가야합니다. 즉, 우리가 자유롭게 선택할 수 있는 수의 개수는 2개이므로 자유도가 n-1이 됩니다.
카이제곱분포
카이제곱분포는 k개의 독립적이고 표준 정규분포를 따르는 확률 변수들의 제곱의 합이 갖는 분포입니다. 카이제곱분포의 수식과 그래프는 아래와 같습니다.[8]


카이제곱분포의 수식은 굉장히 단순합니다. 단순한 만큼 응용되는 분야도 다양합니다. 모분산에 대한 추론, 카이제곱검정 등에서 사용됩니다. 카이제곱검정은 별도의 포스팅에서 다뤄보도록 하고, 모분산의 추론 시에 카이제곱분포가 어떻게 활용되는지만 가볍게 살펴보고 넘어가도록 하겠습니다. 먼저 표본 분산을 수식으로 표현하면 아래와 같습니다.
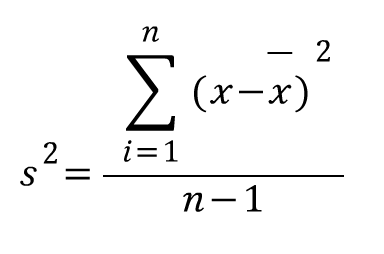
모분산을 살짝 변형한 아래 수식이 자유도가 n-1인 카이제곱 분포를 띈다고 하며, 이를 이용하여 모분산을 추정한다고 합니다.

카이제곱분포를 유도하는 과정이 교과서에서도 생략되어 있어서 추가적으로 조사한 내용을 첨부합니다. 저는 사실 읽어봐도 완전히 이해가 가지 않는 부분이 있는데 그러려니 하고 넘어갔습니다.

f-분포
f-분포는 두 확률 변수 V1, V2가 각각 자유도가 k1, k2이고 서로 독립인 카이제곱 분포를 따른다고 할 때 형성하는 분포로 수식과 그래프는 아래와 같습니다.


f-분포는 f 검정이나 분산 분석에서 많이 활용된다고 합니다. 예를들어 앞서 카이제곱 분포가 모분산의 추정에 사용되었다면 f-분포는 두 모분산의 비율에 대한 추정을 할 떄 사용됩니다. 수식으로 표현해보면 아래와 같습니다.

감마 분포
감마 분포와 베타 분포를 이해하기 위해서는 먼저 감마 함수와 베타 함수를 이해해야 합니다. 먼저 감마 함수를 설명드리겠습니다. 감마 함수는 팩토리얼의 개념을 함수로 일반화하여 표현한 것입니다. 감마 함수에 대한 보다 자세한 내용은 다음의 자료를 참고하시면 됩니다.[10]

감마 함수의 수식과 대표적인 성질을 수식으로 표현하면 아래와 같습니다.

감마 함수에 정수 n을 입력으로 넣으면 (n-1)!를 결과로 얻습니다. 또한 그동안 정수에 머물러 있었던 팩토리알을 복소수 차원으로 확장시켜 주었다고 합니다. 감마 함수를 실수축 위에 그려보면 아래와 같습니다.

감마 분포는 감마 함수를 응용하여 유도할 수 있습니다. 유도 방식은 다음의 자료를 참고해주시면 되며[12] 구체적인 수식과 그래프는 아래와 같습니다. 여기서 k와 θ는 감마 분포의 모수(parameter)이며 k는 그래프의 모양(shape)를, θ는 그래프의 크기를 결정한다고 합니다.
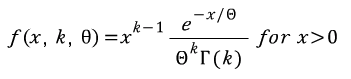

감마 분포는 k번째 사건이 일어날 때까지 걸리는 시간에 대한 연속 확률분포라고 합니다. 즉, 총 k번의 사건이 발생할 때까지 걸리를 시간의 확률 분포로 이해하면 좋을 것 같습니다.
베타 분포
베타 분포를 이해하기 위해서는 마찬가지로 베타 함수에 대해서 이해해야 합니다. 감마 함수가 팩토리알을 일반화하는 함수였다면 베타 함수는 이항 계수(binomial coefficient)를 일반화 한 함수로 이해할 수 있습니다. 이항 계수는 n개 중에 k개를 뽑을 수 있는 조합의 수로 nCk로 흔히 알고 있습니다. 이항 계수를 수식으로 표현하면 아래와 같습니다.

이항 계수 역시 기존에는 자연수에 대해서만 정의가 되어 있었습니다. 이를 일반화한 것이 베타 함수이며 수식과 그래프로 표현하면 아래와 같습니다. (그래프를 찾긴 했으나 이해를 하진 못했습니다 ㅎㅎ)


이는 앞서 살펴본 감마 함수와 밀접한 연관이 있습니다. 이항 계수가 사실은 팩토리알로 이루어져있다는 사실을 떠올려보면 베타 함수를 감마함수로 표현할 수 있다는 것을 이해할 수 있습니다.

이제 베타 분포로 넘어가보도록 하겠습니다. 베타 분포는 두 개의 매개 변수에 의해서 형태가 결정되며 수식과 그래프는 아래와 같습니다.


이러한 베타 분포는 전통적인 강화학습이나 베이지안 추론에서 자주 등장한다고 합니다. 이들을 별로도 다룬 포스팅에서 베타 함수가 어떻게 현실에 적용되는지 살펴볼 수 있도록 하겠습니다.
ps. 감마 분포와 베타분포는 수학적 배경지식이 부족하여 완벽히 이해를 못하고 넘어가는 아쉬움이 있습니다. 추후에 더 공부하여 이해한 내용이 있다면 쉽게 풀어서 내용을 추가하도록 하겠습니다.
디리클레 분포
카테고리형 분포가 이항 분포를 확장시킨 것 처럼 디리클레 분포는 베타 분포의 확장으로 볼 수 있습니다. 베타 분포는 0과 1 사이의 값을 가지는 단일 확률 변수의 베이지안 모형에 사용된다면, 디리클레부포는 0과 1 사이 값을 가지는 다변수 베이지안 모형에서 사용됩니다. 예를 들어 K=3인 디리클레 분포를 따르는 확률 변수로는 (0.2, 0.3, 0.5), (0.5, 0.5, 0), (1, 0, 0) 등이 있습니다. 디리클레 분포의 확률 밀도 함수는 아래와 같습니다.

카테고리형 모형과 마찬가지로 디리클레 분포 역시 k=2일 때는 베타 분포가 됩니다. k=3일 때 디리클레 분포를 시각화 해보면 아래와 같습니다. 디리클레 분포는 베이즈 통계학에서 사전 확률로 자주 사용된다고 합니다.

마치며
지금까지 통계학에서 다루는 기초적인 확률 분포들에 대해서 간략하게 살펴보았습니다. 기본적인 수식과 그래프, 유도된 배경, 사용처 등에 대해서 정리를 해보았습니다. 포스팅을 작성하면서도 수학적인 지식이 부족하여 깊이있게 다뤄보지 못한 부분들이 아쉬움이 남습니다. 통계학과 수학은 놓지 말고 꾸준히 공부해야겠다는 것을 새삼 느끼면서 마무리 하겠습니다.
감사합니다.
Reference
[1] 통계학 입문, 강상욱 외 8인
[2] 이산형 확률변수, 연속형 확률 변수, https://statisticsbyjim.com/basics/probability-distributions/
[3] 베르누이 분포, https://datascienceschool.net/view-notebook/76644ecf24154db687392ccb0eaac644/
[4] 포아송 분포 예제, https://math100.tistory.com/29
[5] 모평균 추정 개념, https://bskyvision.com/489
[6] 표본 표준 편차 유도, https://hsm-edu.tistory.com/13?category=741767
[7] 표본 평균의 표준 편차 유도, https://hsm-edu.tistory.com/16
[8] 카이제곱분포, https://ko.wikipedia.org/wiki/카이제곱분포, 위키피디아
[9] stackexchange, https://ko.wikipedia.org/wiki/%EC%B9%B4%EC%9D%B4%EC%A0%9C%EA%B3%B1_%EB%B6%84%ED%8F%AC
[10] 감마 함수와 실수의 팩토리얼, http://blog.naver.com/PostView.nhn?blogId=a4gkyum&logNo=221041200583&beginTime=0&jumpingVid=&from=search&redirect=Log&widgetTypeCall=true
[11] 감마 함수와 베타함수, https://jjycjnmath.tistory.com/505
[12] 감마 함수로부터 감마 분포 유도, https://blog.naver.com/mykepzzang/220842759639\
[13] 디리클레분포, https://datascienceschool.net/view-notebook/e0508d3b7dd6427eba2d35e1f629d3de/, 데이터 사이언스 스쿨
'갈아먹는 머신러닝 시리즈 > 통계학 기초' 카테고리의 다른 글
| 📊 갈아먹는 통계학 (0) | 2023.10.26 |
|---|---|
| 갈아먹는 통계 기초[4] 가설, 검정, p-value (4) | 2020.04.20 |
| 갈아먹는 통계 기초[3] 표본 추출 (0) | 2020.04.19 |
| 갈아먹는 통계 기초[2] 공분산과 피어슨 상관 계수 (0) | 2020.04.19 |