들어가며
🧑💻 Segment Anything Model github
하나의 모델이 다양한 Computer Vision task를 수행할 수 있다면 어떨까요? 일일이 테스크 별로 모델을 만들 필요가 없어져서 매우 편리하겠죠?
오늘은 메타가 최근 공개한 Segment Anything Model 논문을 리뷰해보았습니다. 논문 제목 답게 저자들은 promptable segmentation이라는 새로운 task를 정의하고, 아주 유연한 비전 모델을 만드는 시도를 했습니다.
과연 메타의 연구진들은 GPT 처럼 computer vision 계의 general AI를 만드는데 성공했을까요? 같이 리뷰해보시죠!
Segment Anything Model 논문 3줄 요약
- Next token prediction으로 학습한 GPT가 온갖 task를 잘한다.
- Computer Vision에서도 이런 만능 모델을 만들고 싶어서 새로운 task, model, data를 개발했다.
- Segmentation은 당연히 잘하고, 다른 테스크들에서도 어느 정도 성능을 보여줬다.
Segmentation Aything Model
먼저 결과부터 보겠습니다. 무엇이든 segmentation한다는 이름답게 이미지에 포함된 물체를 잘 segmentation 해줍니다. 특히나 인상적인건 segmentation 하고자 하는 대상을 점으로 찍을 수도 있고, 박스로 표시할 수도 있고, 심지어 자연어로 지정할 수도 있습니다. 이처럼 segmentation 대상 지정을 유연하게 입력받을 수 있는걸 promptable segmenation이라고 부릅니다.

또한 이미지 안에 포함되어 있는 모든 물체를 segmentation 하는 것도 가능합니다.

다만 세그멘테이션한 마스크가 전경인지 배경인지만 분리해주고, 어느 클래스에 속하는 지는 알려주지 못합니다. 그렇다 하더라도 상당히 활용도가 높아보이는 모델입니다. 그렇다면 이런 SAM 모델을 어떻게 만들었는지 같이 리뷰해보시죠!
Image Segmentation
이미지 안에서 물체의 영역을 마스킹하는 컴퓨터 비전 테스크로 픽셀 단위로 어느 클래스인지 분류해야하는 난이도가 매우 높습니다.
자율주행차나 의료 AI 등의 분야에서 많이 활용됩니다.

주요 기여
Segmentation Anything Model 논문은 어떻게 하면 GPT처럼 general한 Computer Vision 모델을 만들 수 있을지 연구하였습니다. 그 결과로 크게 Task, Data, Model 세 가지 측면에서 기여를 했다고 합니다.
Task
먼저 어떤 테스크로 모델을 학습시켜야 GPT처럼 general한 vision 모델을 만들 수 있을까 고민한 결과, promptable segmentation이라는 새로운 테스크를 직접 고안해내었습니다. 이를 통해서 상당히 유연한 모델을 학습시킬 수 있었다고 합니다.
Data
이 promptable segmentation 테스크를 수행하는 모델을 학습시키기 위한 데이터 셋이 필요했다고 합니다. 직접 휴먼 라벨링과 AI 라벨링을 이용해서 총 10억개의 마스크를 포함한 SA-1B 데이터 셋을 만들었다고 합니다.
Model
마지막으로 이 테스크를 잘 수행하기 위한 모델 구조를 제안했다고 합니다. 그 결과로 Image encoder, Prompt encoder, Mask Decoder로 구성된 모델을 제안하며, 다양한 컴퓨터 비전 테스크들에 대해서 뛰어난 제로샷 성능을 보여주었습니다.
하나씩 자세히 살펴보겠습니다.
Task
NLP 분야에서는 다음에 올 단어를 예측하는 방식으로 학습시킨 GPT가 한번도 학습한적 없는 테스크들을 잘 수행하면서 혁신을 가져왔습니다.

여기서 영감을 받아서 Computer Vision 분야에서도 이런 foundation model을 만들어보고자 시도한 것이 SAM 모델입니다. 그리고 마치 GPT가 앞에 문장을 보고 다음에 올 단어를 예측하는 것처럼 general한 모델을 학습시키기 위해선 어떤 테스크로 모델을 학습시키면 좋을지 고민한 결과가 promptable segmenation입니다.

Promptable Segmentation
Promptable Segmentation은 마스크를 생성하고자 하는 대상을 유연하게 prompt로 지정할 수 있는 테스크입니다. 프롬프트로는 점, 박스, 텍스트 등이 입력될 수 있습니다.

인풋 아웃풋 관점에서 보면 이미지와 프롬프트를 입력받아서 물체에 해당하는 마스크를 출력하는 테스크입니다.

Data
유연하게 동작하는 genral한 AI를 학습시키기 위해서는 상상을 초월하는 데이터가 필요합니다. GPT의 경우, 웹 상의 텍스트들을 크롤링한 Common Crawl을 주요 데이터 셋으로 사용하였습니다.
그런데 segmentation 모델을 학습시키기 위해선 마스크 라벨이 붙어있는 데이터가 필요합니다. 이는 단순 크롤링으로 해결이 안될 뿐더러 제작에 엄청난 수고가 들어갑니다.

때문에 메타는 자체 data engine을 만들어서 전례 없는 규모의 데이터 셋을 직접 만들었다고 합니다. 그 과정에서 사람의 수작업과 AI를 적절히 사용하였습니다. 최종적으로 10억개의 마스크를 포함한 SA-1B 데이터 셋을 공개하였으며, 이는 사람 손을 타지 않고 순수 AI가 라벨링 작업을 진행했다고 합니다.
SA-1B 데이터 셋은 3가지 단계로 나눠서 구축했다고 합니다. 처음에는 사람이 라벨링하고, AI가 보조하다가 점점 AI가 스스로 라벨링을 합니다. 각 단계별 디테일을 알아보겠습니다.

1. Assisted Manual 단계
기존에 공개되어 있는 segmentation 데이터 셋으로 먼저 SAM 모델을 학습시켰다고 합니다. 그리고 새로운 데이터에 대해서 AI가 먼저 segmentation을 해놓으면 사람이 이를 수정했다고 합니다. 이런 방식으로 430만개의 마스크를 라벨링하였으며, 라벨링 하는 와중에도 데이터 쌓이면 모델을 꾸준히 재학습 시켰습니다.

2. Semi-automated 단계
기존의 segmentation 데이터 셋은 배제하고 1단계에서 모은 데이터 셋 만으로 SAM 모델 학습시켰다고 합니다. 그 다음, AI가 먼저 segmentation을 해놓으면 사람이 빠진 것들만 채워넣었다고 합니다. 이미 segmentation 성능이 뛰어나서 사람이 일일이 수정하지 않고, 마스크가 아예 빠져있을 경우에만 추가해줬다고 합니다. 이런 방식으로 마스크 590만개 추가 라벨링을 했습니다. (도합 1020만개)

3. Fully-automated 단계
1, 2 단계에서 모은 마스크 1020만개를 가지로 SAM 모델을 학습시켰습니다. 이걸 가지고 이미지 1100만장에 대해 11억개의 마스크 라벨을 생성한게 SA-1B 데이터 셋입니다.

Model
테스크도 잘 정의했고 데이터도 잘 모았으니 모델링을 할 차례입니다. SAM 모델은 Image Encoder, Prompt Encoder, Mask Decoder로 구성되어 있습니다. 하나씩 살펴보겠습니다.

Image Encoder
먼저 Image Encoder는 Masked auto-encoder 방식으로 학습시킨 Vision transformer를 사용하였습니다. MAE는 이미지를 일정한 크기의 그리드로 나누고 랜덤하게 가린 뒤, 복원하도록 모델을 학습시키는 기법입니다. 아래 모델에서 decoder는 제외하고 encoder만 가져왔다고 합니다.

Prompt Encoder
그 다음 Prompt Encoder는 각 prompt 타입에 맞는 인코딩 방식을 적용했다고 합니다. 점이나 바운딩 박스는 positional encoding을 사용했다고 하고, text는 CLIP 멀티모달 임베딩을 가져왔다고 합니다.

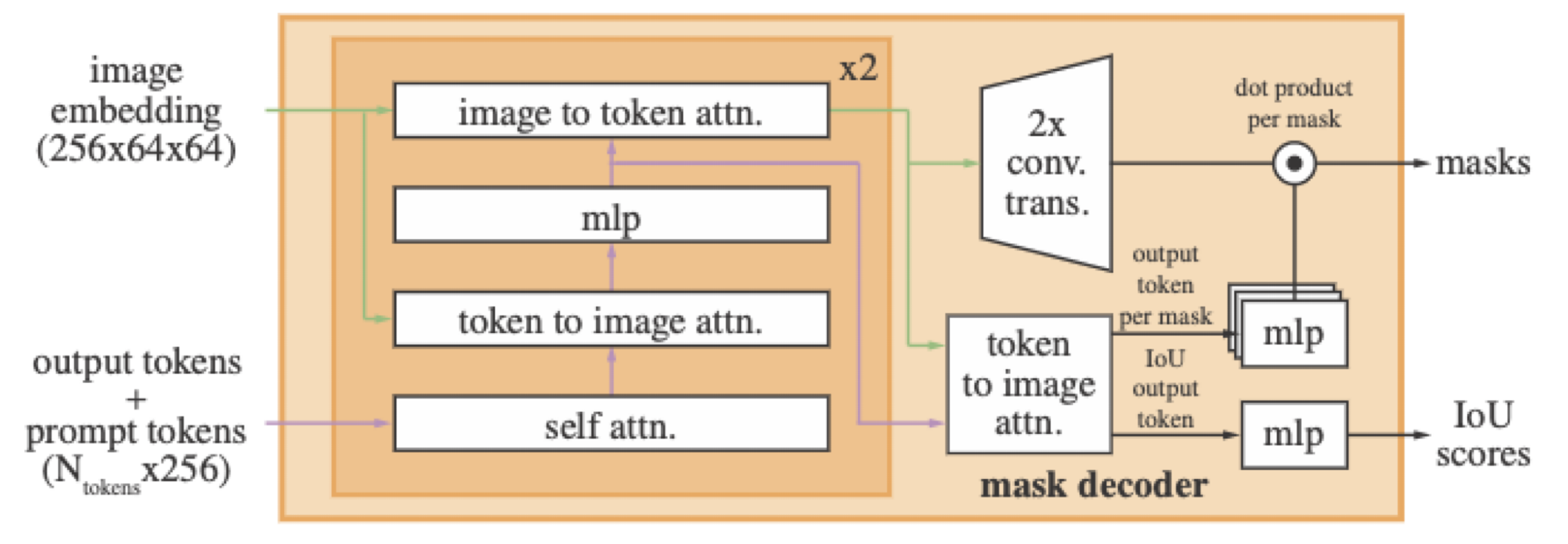
Mask Decoder
이미지 임베딩과 프롬프트 임베딩 간의 cross attention 메커니즘을 적용해준 뒤, 마스크와 IoU를 리턴합니다. Cross attention 메커니즘은 상당히 복잡해서 별도 리뷰에서 자세히 다루겠습니다.
Ambiguity
모델링까지 마쳤으니까 이제 학습만 진행하면 되겠죠? 그런데 promptable segmentation 테스크의 경우 고려해야할 상황이 하나 더 있습니다. 바로 하나의 prompt에 정답이 여러개가 될 수 있는 ambiguity입니다.
예를 들어 아래 예시 이미지에서 첫번째 열의 타조 이미지를 보면 머리 부분에 점이 찍혀있습니다. 이는 전체 타조를 세그맨테이션 해달라는 요청일 수도 있고, 타조의 머리 부분만 세그맨테이션을 해달라는 요청일 수도 있습니다.

이런 애매한 상황을 해결하기 위해서 SAM 모델은 애초에 하나의 프롬프트에 대해 3개의 마스크를 리턴합니다. 그리고 3개 중에 가장 loss 값이 작은 것만 역전파 시키는 방식으로 해결합니다.

Zeroshot Experiments
이렇게 학습시킨 SAM 모델이 과연 GPT 처럼 한번도 학습한 적 없는 테스크들을 잘 수행하는지 실험해봐야겠죠? 논문에서는 총 5가지의 테스크에 대해 실험을 했고, 그 결과 상당히 준수한 성능을 보여주었습니다.

1. Singlepoint Segmentation
먼저 SAM 모델이 학습한 적 없는 기존 23개의 segmentation 데이터 셋들에 대해서 점 찍었을 때 마스크를 얼마나 잘 생성하는지를 기존 SOTA 모델인 RITM과 비교해보았습니다. 주황색과 파란색 막대로 표시된 부분은 각각 SAM과 RITM이 더 뛰어난 성능을 보여준 지표들이고, 점선과 함께 연한 점으로 표시된 지표는 Ambiguity를 고려했을 때 SAM 모델이 얼만큼 더 뛰어난 성능을 보여주었는지 입니다.

생성된 마스크의 퀄리티를 사람 눈으로 비교했을 때에도 모든 부문에서 SAM이 더 뛰어났다는걸 확인할 수 있습니다.

2. Edge Detection
이미지가 주어졌을 때, 테두리를 추출하는 테스크로 기존 edge detection 데이터 셋에 대해서 SOTA 모델들과 비교해보았습니다.

segmentation 모델을 edge detection에 사용하기 위해서 인퍼런스를 살짝 변형했다고 합니다. 자세한 디테일은 생략하겠습니다.
그 결과 기존 edge detection SOTA 모델을 뛰어넘지는 못했지만, 비빌만한 성능올 보여주었다고 합니다.

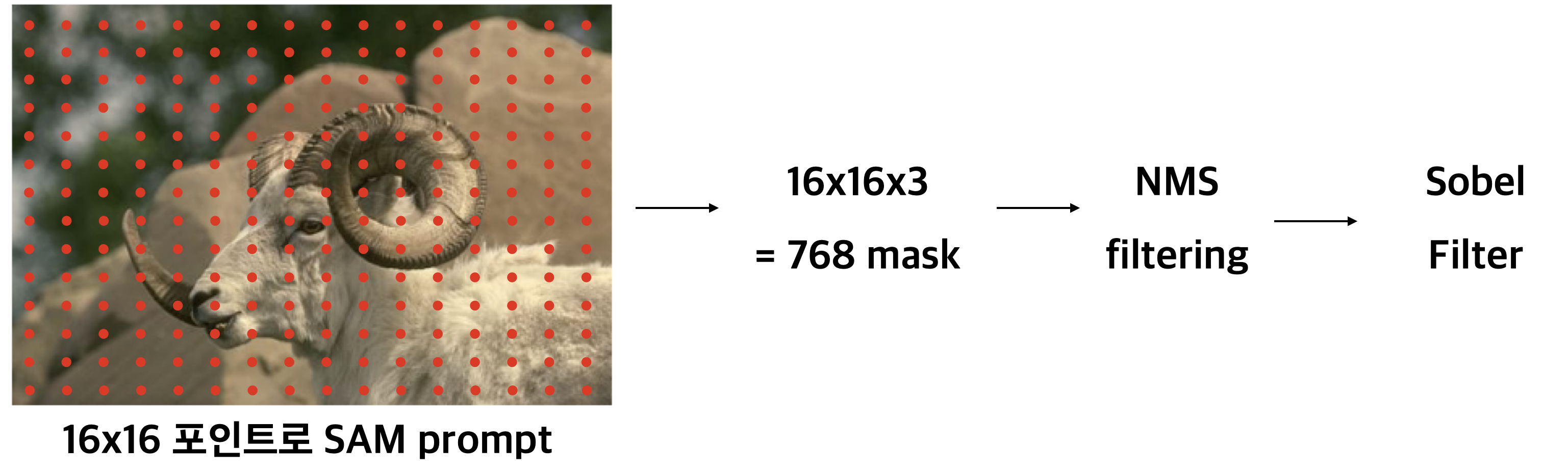
3. Object Proposal
object detection 분야에서 많이 연구된 분야로 물체가 있을만한 후보 영역을 찾는 테스크입니다.
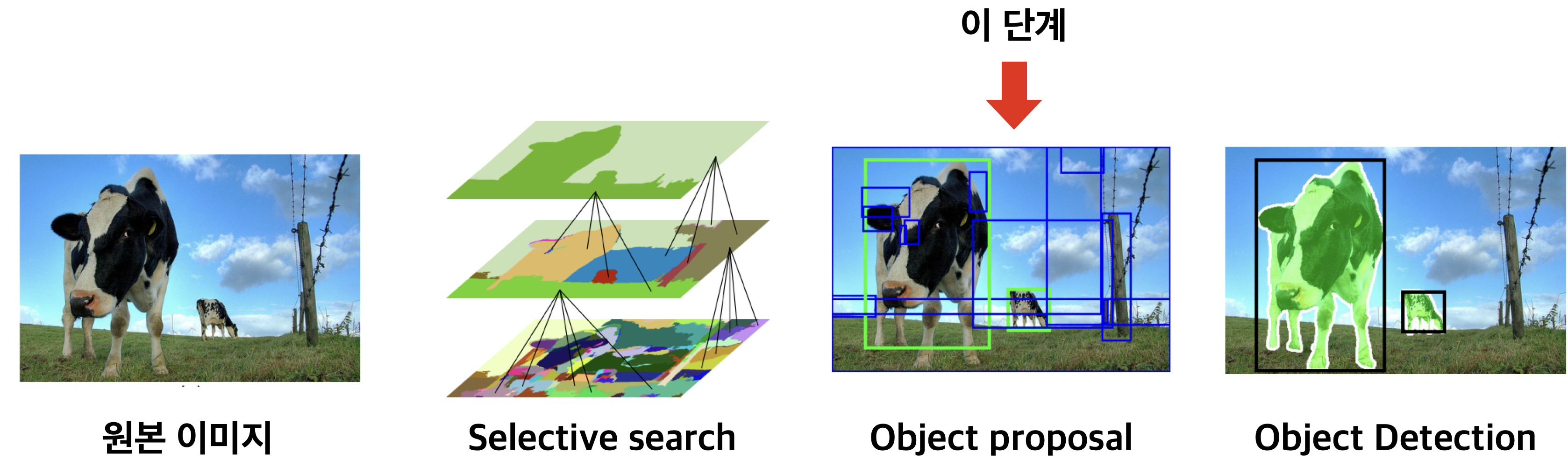
마찬가지로 object proposal을 수행하기 위해서 인퍼런스 과정을 살짝 변행했습니다.

그 결과 작은 물체를 제외하고는 SOTA 시스템과 비슷한 성능을 보였다고 합니다. 그리고 rare한 물체는 더 잘 찾는 것으로 보아 더 general한 특징이 있었다고 합니다.

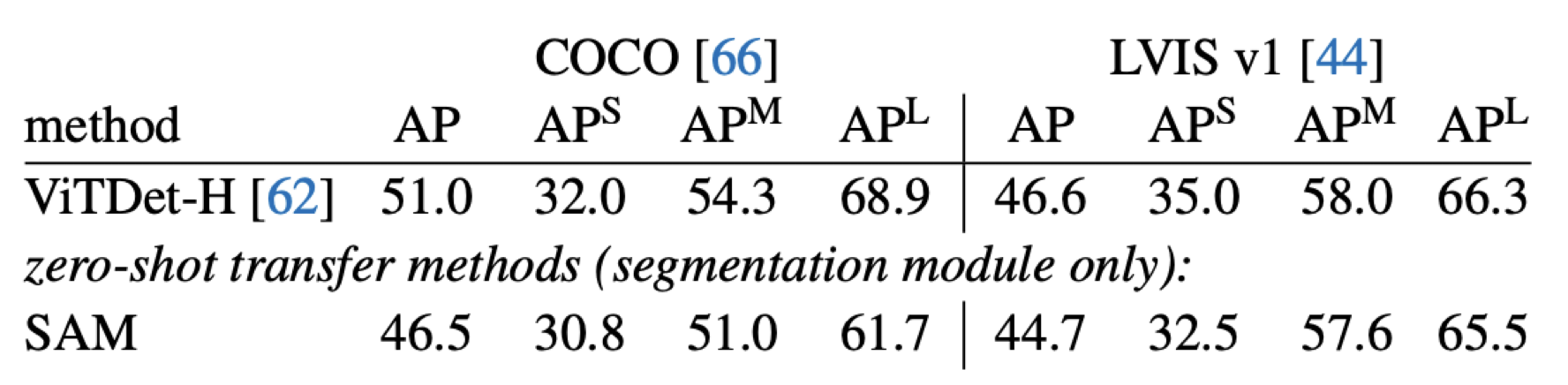
4. Instance Segmentation
Object Detection 결과로 출력된 물체에 대해서 Segmentation을 하는 테스크입니다.

정량적인 metric에서는 다소 밀리나, 정성적인 마스크 퀄리티 평가에서는 압도했습니다. 특히 데이터 셋의 품질이 안좋을수록 SAM 모델이 낮은 평가를 받았다고 합니다.
5. Text to mask
마지막으로 가장 모험적인 시도인 텍스트로 세그멘테이션 하기입니다.

어느 정도 텍스트 기반의 세그멘테이션 구현하였으며, 다른 프롬프트와도 결합 가능해 보였습니다. 그러나 정량적인 평가가 논문에서 빠졌고, 데모에서도 제외된 것으로 보아 성능이 뛰어나진 않았을 것으로 추측합니다.

정리
정리해보면 메타의 연구진들은 Computer Vision계의 Foundation Model을 만들자는 문제 의식에서 출발해서 Task, Data, Model을 직접 고안해내었습니다. 그리고 그 결과로 나온 것이 SAM입니다. 그렇다면 원래 의도했던 vision 계의 GPT를 만들었다고 볼 수 있을까요?
개인적인 생각으로는 하나의 모델이 다양한 테스크를 수행했다기 보단, 많은 테스크를 포괄하는 테스크로 모델을 학습시키고, subtask들로 실험한 느낌이 들었습니다. 완전히 학습한 적 없는 테스크라고 느껴졌던 건 text segmentation 하나였습니다. 때문에 범용성 측면에서 아쉬움이 남았습니다.

이 외에도 리뷰에서 채 못다룬 데이터 셋 형평성 분석, prompt encoder와 mask decoder 디테일, 세부 학습 방법, 실험 결과들이 있으니 궁금하신 분들은 논문을 읽어보시거나 댓글로 질문을 남겨주세요!
저는 다음에 더 재밌는 AI 논문 리뷰로 돌아오겠습니다. 🐧 펭바!
'퍼펭스쿨 AI 논문 리뷰' 카테고리의 다른 글
| LMM 환각을 해결해주는 딱따구리! Woodpecker 논문 리뷰! (0) | 2023.11.02 |
|---|---|
| GPT4 이제 눈까지 떠버렸다👀 GPT-4V 논문 리뷰 (1) | 2023.10.27 |
| AI들이 차린 게임회사🕹️ chatdev 리뷰 (0) | 2023.10.24 |
| 라마, 알파카, 비쿠나 오픈소스 챗봇 낙타들🐪 총정리! (0) | 2023.10.24 |
| AI들끼리 살고 있는 마을🏡 Generative Agent 리뷰 (4) | 2023.04.18 |