지난 글
갈아먹는 BigQuery [2] 빅쿼리 스키마 및 데이터 모델
갈아먹는 BigData [1] MapReduce 이해하기
들어가며
지난 시간에 BigQuery의 큰 특징 중 하나인 Columnar Storage에 대해서 알아보았습니다. 이번에는 또 다른 특징인 트리 기반의 쿼리 분산 실행에 대해서 알아보겠습니다. 컬럼 기반으로 저장된 데이터에 대해서 어떻게 SQL문을 적용하는 지에 대한 세부적인 내용 보다는 어떻게 방대한 양의 서버들에 SQL 쿼리를 분산시키고 이를 수합하는 지에 초점을 맞추어 진행하겠습니다.
(지난 포스팅과 마찬가지로 빅 쿼리의 전신인 Dremel의 논문에 기반합니다.)
Tree Architecture

Dremel은 입력 쿼리가 들어오면 execution tree를 생성합니다. 트리는 root server, intermediate servers, leaf searvers로 구성됩니다. 루트 서버는 사용자로부터 SQL 쿼리를 입력받습니다. 루트 서버는 이를 분산 노드들에서 실행할 수 있도록 작은 SQL문들로 쪼개어 새롭게 SQL문을 생성한 다음 intermediate 서버로 내려보냅니다. intermediate 서버들도 전달받은 쿼리를 더 작게 쪼개어 리프 노드로 내려보냅니다. 리프 노드는 실제 파일 시스템(빅 쿼리의 경우 Colossus)에 저장된 데이터를 읽어와서 쿼리 연산을 수행하고 결과를 부모 노드에게 전달합니다. 이를 순차적으로 취합하여 최종 쿼리 수행 결과를 얻게 됩니다.
간단한 예시를 통해서 어떻게 SQL 문이 쪼개지고, 분산 노드들에게 전달되는 지를 알아보겠습니다.
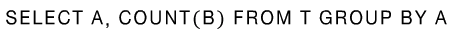
루트 서버는 이 SQL을 입력받은 다음, 테이블 T의 메타 데이터를 확인한 뒤, 다음과 같이 쿼리를 재생성합니다.

첫 번째 줄부터 살펴보겠습니다. 원본 테이블 T 대신에 R11부터 R1n을 union한 테이블로부터 sum을 계산합니다. 이 때 R11부터 R1n은 루트 노드(레벨 1)가 1번부터 n번까지의 intermediate 노드들에게 분산 시킨 쿼리의 결과들을 의미합니다.
노드들에게 쿼리는 어떻게 분산 시킬까요? 먼저 테이블 T는 horizontally partitioned 되어 있습니다. 테이블 하나에 저장되는 레코드의 양이 많아서 이를 횡으로 나누어 여러 물리 머신에 나눠 저장한 것입니다. 분산된 테이블 T11부터 T1n에 대하여 각각 쿼리를 수행하도록 SQL을 쪼개어 준 뒤, 트리의 하위 노드들에 전달합니다. Intermediate 노드들도 같은 작업을 반복하여 연산을 더 작게 쪼갭니다. 이렇게 연산량이 작아진 SQL문에 리프 노드에 도달하고 여러 대의 머신에서 병렬적으로 연산을 진행하게 되는 것입니다.
Query Dispatcher
Dremel은 여러 사용자가 동시에 쿼리를 요청할 수 있는 시스템이어야 합니다. 이를 위해서 쿼리들의 우선 순위를 정하고 스케쥴링 및 로드 밸런싱을 해주는 Query Dispatcher가 있습니다. Dremel에서 특정 쿼리에 대한 연산량을 slot(슬럿)이라는 단위로 계산합니다. 슬럿은 리프 서버에서 쿼리를 수행하는 단일 쓰레드를 의미합니다. 만일 리프 서버가 3000대가 있고 각각이 8개의 쓰레드를 돌린다면 총 24000개의 슬럿이 있는 것입니다. 만일 100,000개의 분산 테이블에 저장된 테이블에 대한 쿼리가 들어올 경우 각 슬럿에 5개의 테이블 조각을 할당하면 처리가 가능합니다.
쿼리 디스패쳐는 이러한 스케쥴링 외에도 fault tolerence를 수행합니다. 특정 머신에서 쿼리를 수행하는 속도가 지나치게 느리면 이를 다른 노드에게 일임합니다. 또한 특정 데이터 복사본에 접근이 불가능할 경우, 다른 복사본에 접근하도록 한다는 등의 동작을 수행합니다. 덧붙여 쿼리 디스패쳐는 결과를 리턴하기 이전에 반드시 스캔해야하는 최소 테이블 조각 비율을 준수하는 역할도 수행합니다. 예를 들어 98%라면 원본 테이블의 98%에 해당하는 분산 테이블을 스캔하기 이전에는 결과를 리턴하지 않도록 합니다.
In Memory Query Execution
이제 리프 노드에서 SQL을 실행하여 얻은 데이터들이 어떻게 상위 노드로 전달되는지, 노드들 간에 데이터 교환은 어떻게 이루어지는 지 알아보겠습니다. 빅 쿼리에서는 이렇게 노드들 간에 데이터 교환 작업을 셔플링이라고 부릅니다. 셔플링은 MapReduce 논문에서 제안된 개념으로 생소하신 분들은 지난 포스팅을 참고해주시기 바랍니다.
빅 쿼리에서는 셔플링을 row 단위로 노드들 간에 데이터를 주고 받는 것을 의미합니다. 이를 위해서 세 가지 high level API를 구현하였고, 이를 기반으로 셔플링 구조를 설계하였습니다.
Producer (producer_id) {
void SendRow(row, consumer_id) : Called to send a row to a given consumer
on behalf of this producer.
}
Consumer (consumer_id) {
string ReceiveRow() : Called to receive one row for this consumer.
}
Controller {
StartShuffle() : Called before any producers or consumers start sending or
receiving rows.
EndShuffle() : Called after all producers and consumers have successfully
sent and received all rows.
}
Producer는 데이터 처리 작업을 진행한 결과를 다음 노드에게 전달해주는 역할을 하며, Consumer는 이전 노드에서 전달한 데이터를 수신하는 역할을 합니다. 하나의 워커 노드 안에는 이러한 Producer와 Consumer 모듈이 모두 들어있습니다. 그리고 Controller API를 통해서 데이터를 주고 받는 과정을 제어합니다. 이런 과정을 통해서 데이터를 repartitioning하고, 동적 SQL 계획에 적합하게끔 셔플링을 진행한다고만 나와있습니다. (이 부분에 대한 자료가 부족하여 추상적인 수준만 알고 넘어가겠습니다.)
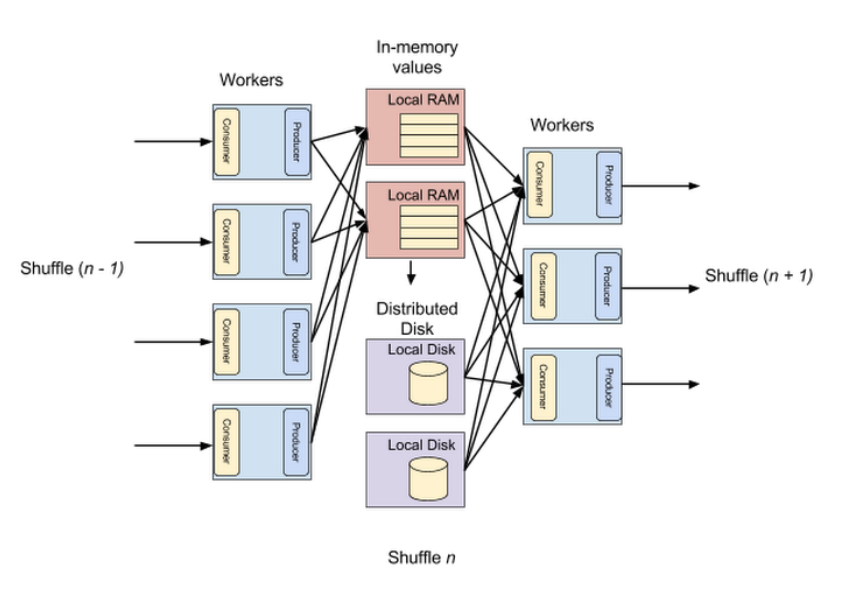
이러한 빅 쿼리의 셔플 구조는 기존의 MapReduce 구조와 크게 두 가지 측면에서 차이가 있습니다. 먼저 모든 연산과 데이터 통신을 디스크가 아닌 메모리 단에서 이루어지도록 하였습니다. Jupiter 기반 고속 네트워크를 통해서 shared memeory abstraction를 기반으로 Producer는 자신이 처리한 데이터를 메모리에 직접 출력합니다. 이는 local disk 공간에 파일을 출력한 뒤 마스터에게 알려주는 MapReduce와 큰 차이를 보입니다.
다음으로 빅 쿼리에서는 셔플링 과정이 모두 끝나기 전에 repartition된 데이터는 곧바로 다음 데이터 처리 파이프라인을 수행할 수 있습니다. 이는 역시 모든 셔플링 과정이 끝난 이후에 리듀스 과정을 수행할 수 있었던 MapReduce와 큰 차이점을 보이며 성능 상의 향상을 가져온다고 설명합니다.
마치며
지금까지 Big Query가 어떻게 SQL 쿼리를 실행하는 지를 아주아주 추상적인 관점에서 훑어보았습니다. 이를 정리해보면 아래와 같습니다.
0. 테이블 형식의 데이터는 횡적으로 쪼개져서 분산 파일 시스템에 저장되어 있다.
1. 노드들 간에 트리 구조를 만든다. SQL이 입력되면 이를 잘게 쪼개어 하위 노드에 전달한다.
2. 리프 노드들은 분산 파일 시스템과 통신을 통해 SQL 문을 실행하고, 그 결과를 부모 노드에 전달한다.
3. 부모 노드들은 다시 이를 합쳐서 자신의 부모 노드에 전달하며, 루트 노드에 도달하면 최종 SQL 결과를 리턴한다.
4. SQL을 실행하는 연산의 가장 작은 단위는 슬럿이다. 특정 SQL에 필요한 슬럿 수는 빅 쿼리가 동적으로 계산한다.
5. 슬럿을 할당하고 전체 쿼리 수행을 조율하며 falult tolerance를 보장하는 Query Dispatcher라는 모듈이 있다.
6. 노드들 간에 데이터를 주고 받는 셔플링은 모두 메모리 기반으로 실행되어 성능을 극대화 한다.
구체적인 셔플링 구조나 알고리즘에 대하여 더 알고 싶었으나, 공개된 자료가 여기까지여서 다소 추상적인 레벨 정도만 알고 넘어가서 다소 아쉬움이 남습니다. 추후에 자료를 더 찾게 되면 내용을 보강해보겠습니다.
감사합니다.
Reference
[1] Dremel: Interactive Analysis of Web-Scale Datasets, google
[2] BigQuery Slot, https://cloud.google.com/bigquery/docs/slots?hl=ko, google cloud
[3] In Memory Query Execution, google cloud
[4] Separation of storage and compute in BigQuery, google cloud
[5] 갈아먹는 BigData[1] MapReduce, https://yeomko.tistory.com/31
'갈아먹는 엔지니어링 시리즈 > 빅데이터' 카테고리의 다른 글
| 갈아먹는 BigData[2] HDFS(하둡 분산 파일 시스템) (1) | 2020.04.23 |
|---|---|
| 갈아먹는 BigData [1] MapReduce 이해하기 (1) | 2020.04.16 |
| 갈아먹는 BigQuery[4] 빅쿼리 아키텍쳐 (1) | 2020.04.14 |
| 갈아먹는 BigQuery [2] 빅쿼리 스키마 및 데이터 모델 (1) | 2020.04.13 |
| 갈아먹는 BigQuery [1] 빅쿼리 소개 (3) | 2020.04.11 |