지난 글
갈아먹는 Code Refactoring [1] 코드 리팩토링의 즐거움
들어가며
앞선 포스팅에서 코드 리팩토링의 개념과 중요성에 대해서 알아보았습니다.
이번 포스팅에서는 간단한 파이썬 코드를 작성해보고 이를 단계별로 리팩토링 해보면서
리팩토링의 기본적인 개념을 익혀보도록 하겠습니다.
예제 소스코드는 직접 작성하였으며, 다음 레파지토리에서 클론 받으실 수 있습니다.
https://github.com/yeomko22/python-refactoring
yeomko22/python-refactoring
python code refactoring example. Contribute to yeomko22/python-refactoring development by creating an account on GitHub.
github.com
0. 리팩토링 전 소스코드 살펴보기
예제 코드는 네이버 뉴스에 특정 키워드 검색 결과를 받아와서 기사 제목만 추출하여 텍스트 파일에 쓰는 코드입니다.
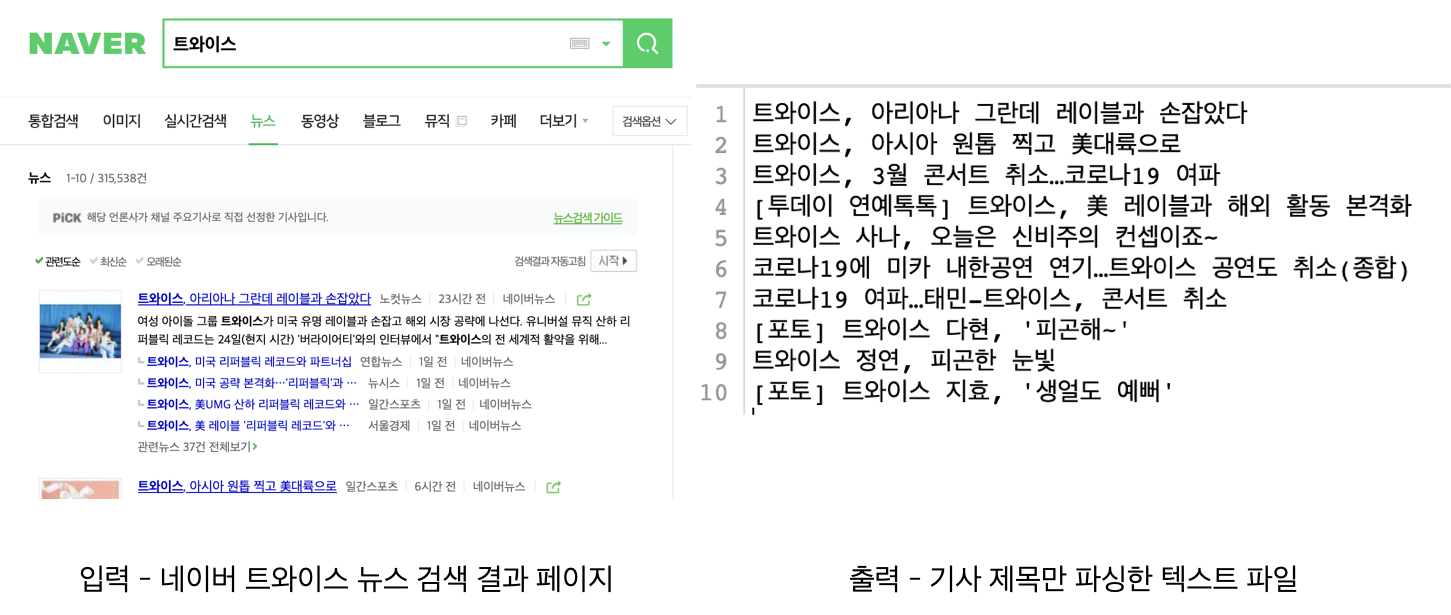
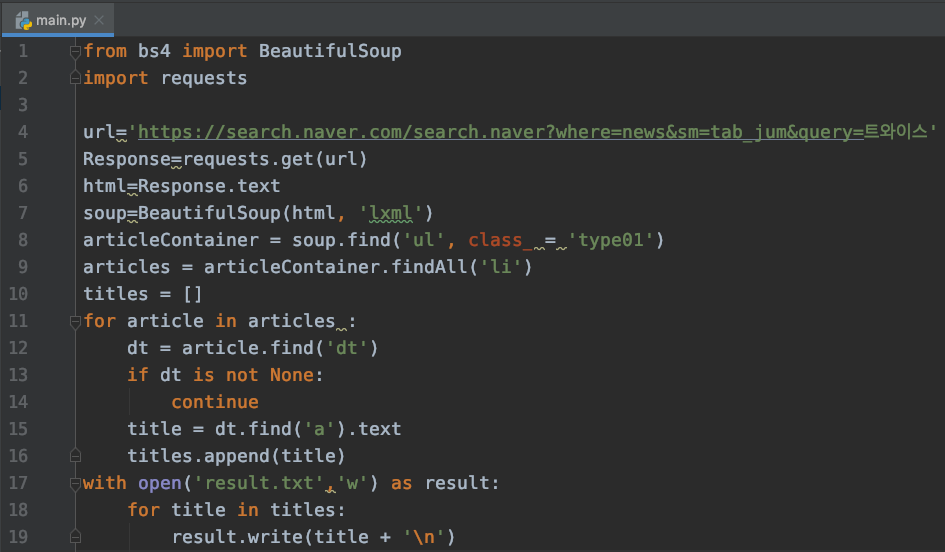
이제 이 코드를 단계별로 리팩토링 해보도록 하겠습니다. 리팩토링은 아래 순서로 진행하며, 적용 결과는 브랜치로 분기되어 있습니다.
1. lint 적용하기 (refactoring/lint)
2. 추상화 적용하기 (refactoring/abstraction)
3. 모듈화 적용하기 (refactoring/moulization)
4. 테스트 코드 작성하기 (refactoring/testcode)
1. lint 적용하기
$ git checkout refactoring/lintlint란 프로그래밍 언어에서 권장하는 코딩 스타일, 혹은 코딩 컨벤션입니다. 파이썬은 PEP8을 일반적으로 권장합니다. lint를 어긴다고 해서 에러가 나는 것은 아니지만, 이를 잘 지켜주는 것은 중요합니다. lint는 팀원들 간의 코딩 스타일을 통일시켜주고, 잠재적인 에러의 가능성을 줄여주기 때문입니다.
그렇다면 위 소스코드에서 lint에 어긋나는 부분은 어디일까요? 먼저 IDE에서 노란줄로 표시되어 있는 부분이 lint를 어긴 부분들입니다. 해당 부분에 커서를 올려놓으면 다음과 같은 문구를 확인할 수 있습니다.

위 메세지는 = 앞 뒤에 권장되어지지 않는 공백을 넣어주었기 때문에 PEP8 규칙을 어겼다고 지적해줍니다. 이와같이 lint는 변수명을 snake_case 스타일로 해야한다던가, 클래스 명을 CamelCase로 해야한다던가, 라인이 지나치게 길다던가, 하나의 함수가 너무 많은 줄을 포함하고 있는다는 등의 경고 메세지를 보여줍니다. 이를 잘 지켜주면 코드가 어느 정도 깔끔해집니다.
IDE에서 노란줄로 표기하는 것 이외에 pylint라는 프로그램을 사용하면 훨씬 더 엄격한 lint 검사를 진행할 수 있습니다. 아래 명령어를 통해서 lint 검사를 진행해보겠습니다.
$ pip install pylint
$ pylint main.py
pylint 수행 결과 해당 소스 코드에서 lint에 어긋나는 문법들을 표기해주고, 이를 점수로 환산해주며, 현재는 1.67 점입니다. 그렇다면 이제 lint 규칙을 준수하도록 리팩토링 해보겠습니다.
main.py
"""
Naver News Crawler
"""
import requests
from bs4 import BeautifulSoup
def main():
"""
1. get article list page html from naver news.
2. parse article titles from html
3. write article titles into a text file.
"""
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=트와이스'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
article_container = soup.find('ul', class_='type01')
articles = article_container.findAll('li')
titles = []
for article in articles:
data_table = article.find('dt')
if not data_table:
continue
title = data_table.find('a').text
titles.append(title)
with open('result.txt', 'w') as result:
for title in titles:
result.write(title + '\n')
if __name__ == '__main__':
main()
먼저 파일의 머리 부분과 함수의 시작 부분에 각각 주석을 넣어주었습니다. 이를 docstring이라 부릅니다. PEP8은 이러한 docstring을 요구하긴 하지만 개인적으로는 이 lint는 무조건 따르기보다는 상황에 맞게 적절히 넣어주는 것이 좋은 것 같습니다.
다음으로 전역으로 선언되어 있었던 변수들을 main이라는 함수 안으로 한번 감싸주었으며, 공백 역시 PEP8에서 권장하는 방식으로 조정하였습니다. 또한 Response, articleContainer 등의 변수명 역시 response, article_container 등으로 변경해주었습니다.
추가적으로 if data_table is not None과 같은 문법은 if not data_table로 단순화시켰습니다. pylint를 다시 실행한 결과, 점수를 10,0으로 맞췄습니다. 그러나 모든 경우에 lint 점수를 10점으로 맞추는 것에 집착하는 것은 좋지 못하며, 유연하게 적용하는 것이 중요합니다.

2. 추상화 적용하기
$ git checkout refactoring/abstractionmain.py
"""
네이버 뉴스의 특정 키워드를 검색하여 나온
기사들의 제목을 추출하여 텍스트 파일에 저장하는 크롤러
"""
import requests
from bs4 import BeautifulSoup
def get_html_from_url(url):
response = requests.get(url)
html = response.text
return html
def parse_article_titles(html):
soup = BeautifulSoup(html, 'lxml')
article_container = soup.find('ul', class_='type01')
articles = article_container.findAll('li')
titles = []
for article in articles:
data_table = article.find('dt')
if not data_table:
continue
title = data_table.find('a').text
titles.append(title)
return titles
def write_titles(titles, filename):
with open(filename, 'w') as result:
for title in titles:
result.write(title + '\n')
def naver_news_titles_crawl(keyword):
url = f'https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}'
html = get_html_from_url(url)
titles = parse_article_titles(html=html)
write_titles(titles=titles, filename=f'{keyword}.txt')
if __name__ == '__main__':
naver_news_titles_crawl(keyword='트와이스')
먼저 html 다운로드, 파싱, 텍스트 파일 출력 기능을 각각 함수로 분리하였습니다. 그리고 함수명에서 각각의 기능을 유추할 수 있도록 네이밍을 하였으며, main 함수 역시도 naver_news_titles_crawl 이라는 이름으로 변경하였습니다.
코드를 읽어보면 html을 다운받고, titles를 추출한 다음, 텍스트 파일에 쓰는구나를 알 수 있습니다. 이러한 추상화를 통해서 개발자는 전체 코드의 진행 흐름을 파악하기 편해지며 기능별로 나뉘어져 있기 때문에 디버깅과 유지 보수가 편해집니다.
덧붙여 함수명과 파라미터만으로 충분히 설명이 된다고 판단하여 불필요한 docstring은 삭제하였습니다. 이는 lint에 반하지만, 불필요한 주석은 오히려 가독성을 해치므로 적절히 판단하여 반드시 필요한 주석만 다는 것이 바람직합니다.
3. 모듈화 적용하기
$ git checkout feature/modularization현재 우리는 main.py 파일 하나에서만 작업을 진행했습니다만, 프로젝트의 규모가 커질 수록 하나의 파일에 모든 코드를 작성하는 것은 복잡성을 키우고 가독성을 떨어뜨립니다. 따라서 기능 별로 파일을 적절하게 분리하고, 이를 가져와 사용하도록 재구성하는 작업이 필요하며, 이를 모듈화라고 합니다.
우리의 예제 코드를 기준으로 좀 더 복잡한 크롤러를 개발한다고 상상해보겠습니다. 파싱해야 하는 html의 종류가 늘어날 수록 그에 해당하는 파싱 함수도 늘어날 것입니다. html을 다운받거나, text 파일에 출력하는 함수는 유틸성 함수들입니다. 따라서 이를 적절히 파일로 나누어 준다면, 프로젝트가 더 복잡해지더라도 유연하게 확장할 수 있습니다.
parser.py
from bs4 import BeautifulSoup
def parse_article_titles(html):
soup = BeautifulSoup(html, 'lxml')
article_container = soup.find('ul', class_='type01')
articles = article_container.findAll('li')
titles = []
for article in articles:
data_table = article.find('dt')
if not data_table:
continue
title = data_table.find('a').text
titles.append(title)
return titles
util.py
import requests
def get_html_from_url(url):
response = requests.get(url)
html = response.text
return html
def write_items(items, filename):
with open(filename, 'w') as result:
for item in items:
result.write(item + '\n')
write_titles 함수의 경우 범용성을 넓히기 위해서 write_items로 고쳤습니다.
naver_news_crawl.py
"""
네이버 뉴스의 특정 키워드를 검색하여 나온
기사들의 제목을 추출하여 텍스트 파일에 저장하는 크롤러
"""
import parser
import util
def crawl_article_titles(keyword):
url = f'https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}'
html = util.get_html_from_url(url)
titles = parser.parse_article_titles(html=html)
util.write_items(items=titles, filename=f'{keyword}.txt')
if __name__ == '__main__':
crawl_article_titles(keyword='트와이스')
main.py는 더 알아보기 쉽게 naver_news_crawl로 고쳤습니다. 그리고 기사 제목을 가져와 텍스트 파일에 출력하는 함수명을 crawl_article_titles로 고쳤습니다. 이를 통해서 개발자가 파일명과 함수명만 보고도 기능을 짐작할 수 있도록 하였습니다. 또한 앞서 모듈로 분리한 parser와 util을 import 하여 사용합니다.
이를 통해서 네이버 뉴스 크롤러에 새로운 기능이 추가된다 하더라도 복잡성의 증가 없이 깔끔하게 확장할 수 있게 되었습니다.
4. 테스트 코드 작성하기
지금까지 리팩토링을 진행해봤습니다. 한 덩어리로 뭉쳐져 있을 때에는 잘 보이지 않았던 것들이 기능 별로 파일과 함수로 나누니 더 명확해졌습니다. 이제 이 각각의 함수들이 제대로 동작하는지 여부를 테스트 하는 유닛 테스트를 작성해보겠습니다. 작은 단위의 프로젝트에서는 굳이 테스트 코드의 작성이 필요 없지만, 프로젝트의 규모가 커질 수록 테스트 코드의 중요성은 점점 더 커집니다. 적절한 리팩토링과 테스트 코드의 꾸준한 작성은 프로젝트가 아무도 알아보지 못하는 코드로 변하지 않도록 돕습니다.
테스트 코드 작성 전에 디렉터리 구조를 잡아보겠습니다. core라는 폴더 아래에 우리가 지금까지 작성한 소스 코드를 옮겨주고, tests라는 폴더 아래에 parser를 테스트하는 파일을 생성해줍니다.

test_parser.py
import unittest
import requests
from core import parser
class ParserTestCase(unittest.TestCase):
def test_parse_article_titles(self):
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=트와이스'
html = requests.get(url, 'lxml').text
titles = parser.parse_article_titles(html)
print(titles)
self.assertEqual(len(titles), 10)
if __name__ == '__main__':
unittest.main()
테스트는 샘플 url을 불러와서 이를 파싱한 다음, titles의 길이를 검사하도록 구성했습니다. 정상적으로 파싱을 했다면 10개의 기사 제목이 담겨 있어야합니다. 한편 기사 목록은 변경될 수 있으므로 내용에 대한 검사를 추가하지는 못했지만, 개발자가 직접 눈으로 파싱 결과를 확인할 수 있도록 titles를 출력해주었습니다.
테스트는 다음 명령어를 통해서 진행할 수 있으며, 결과는 아래와 같습니다.
# tests 폴더 안에 모든 유닛 테스트 파일 실행
$ python -m unittest discover tests -v
마치며
지금까지 작은 크롤러 프로젝트를 단계별로 리팩토링하는 과정을 함께 진행해보았습니다. 대학원이나 회사에서 파이썬으로 딥 러닝 개발을 하시는 분들이 많이 계십니다. 특히나 딥 러닝 리서치 코드는 복잡한 텐서 연산을 반복하기 때문에 리팩토링에 신경을 쓰지 않을 경우, 작성자 본인만 알아보는, 아니 본인도 알아보기 힘든 결과물이 나오기 쉽습니다. 따라서 항상 리팩토링의 중요성을 인지하고 알아보기 쉬운 코드를 작성하는 습관을 들이는 것이 중요합니다.
코드 리팩토링에 관한 좋은 자료를 추천하면서 이만 마치겠습니다.
감사합니다.
https://www.slideshare.net/KennethCeyer/pycon-korea-2018-109833085
우아하게 준비하는 테스트와 리팩토링 - PyCon Korea 2018
더 많은 샘플코드는 아래 주소에서 보실 수 있습니다. https://github.com/KennethanCeyer/pycon-kr-2018
www.slideshare.net
https://www.slideshare.net/KennethCeyer/ai-gdg-devfest-seoul-2019-187630418
AI 연구자를 위한 클린코드 - GDG DevFest Seoul 2019
올바른 코드 작성을 고민하는 연구자들을 위하여 - 클린코드는 여러분의 코드를 복잡한 패턴으로 구현하여 시간을 잡아먹는, 겉만 화려한 장식이 아닙니다. 모델을 구현하고, 또 그것을 테스트 할 때 이것이 정말 올바른 코드인지 궁금하셨나요? 이 세션에서는 연구 모델을 작성할 때 발견할 수 …
www.slideshare.net
http://www.yes24.com/Product/Goods/59626179
Clean Code 클린 코드 - YES24
www.yes24.com
'갈아먹는 엔지니어링 시리즈 > 파이썬 기초' 카테고리의 다른 글
| pycharm IDE 설치 (0) | 2023.10.24 |
|---|---|
| jupyter notebook 설치 및 사용법 정리 (0) | 2023.10.24 |
| 갈아먹는 Code Refactoring [1] 코드 리팩토링의 즐거움 (0) | 2020.02.25 |
| 갈아먹는 파이썬[2] @ decorator란? (1) | 2019.09.18 |
| 갈아먹는 파이썬 [1] generator와 yield (2) | 2019.09.14 |