들어가며
2020년을 맞이하여 가장 먼저 Object Detection을 공부해보기로 결심하여, 논문들을 차례로 리뷰해보려 합니다. (열정 충만!)
그 첫 번째 논문으로 딥 러닝 기반의 Object Detection의 시작을 연 R-CNN[1]을 살펴 보았습니다.
이를 시작으로 object detection 관련 논문들을 차례로 쭉쭉 읽어나갈 예정입니다.
영향력: 인용 횟수가 무려 11000회에 달하며, 이후에 이어지는 R-CNN 시리즈들의 시작을 연 논문입니다.
주요 기여: CNN을 사용하여 object detection task의 정확도와 속도를 획기적으로 향상시켰습니다.
성능: Pascal VOC 2010을 기준으로 53.7%이며, 이미지 한 장에 CPU로는 47초, GPU로는 13초가 걸립니다.
R-CNN 모델
논문에 기재된 R-CNN의 전반적인 흐름은 다음과 같습니다.

아래는 R-CNN의 흐름을 더 보기 좋게 그린 도표입니다.
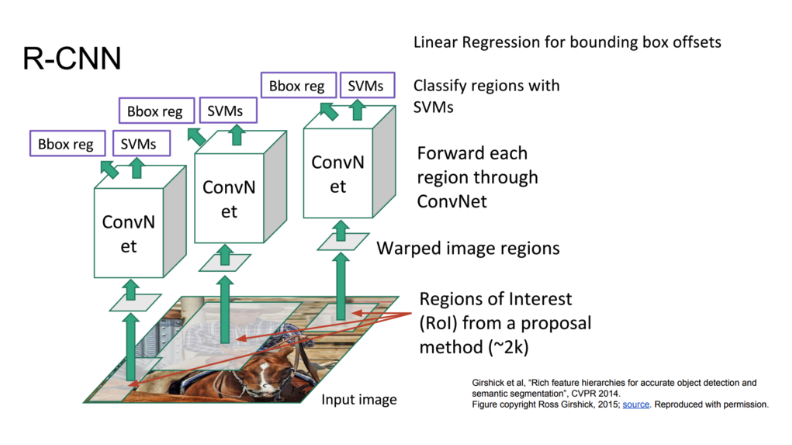
R-CNN이 Object Detection을 수행하는 알고리즘은 다음과 같습니다.
1. 입력 이미지에 Selective Search 알고리즘을 적용하여 물체가 있을만한 박스 2천개를 추출한다.
2. 모든 박스를 227 x 227 크기로 리사이즈(warp) 한다. 이 때 박스의 비율 등은 고려하지 않는다.
3. 미리 이미지 넷 데이터를 통해 학습시켜놓은 CNN을 통과시켜 4096 차원의 특징 벡터를 추출한다.
4. 이 추출된 벡터를 가지고 각각의 클래스(Object의 종류) 마다 학습시켜놓은 SVM Classifier를 통과한다.
5. 바운딩 박스 리그레션을 적용하여 박스의 위치를 조정한다.
이제 각각의 단계별로 어떠한 계산 과정을 거치고, 구체적으로 R-CNN이 무엇을 학습하는지 알아보겠습니다.
1. Region Proposal
Region Proposal이란 주어진 이미지에서 물체가 있을법한 위치를 찾는 것입니다.
R-CNN은 Selective Search라는 룰 베이스 알고리즘을 적용하여 2천개의 물체가 있을법한 박스를 찾습니다.
Selective Search는 주변 픽셀 간의 유사도를 기준으로 Segmentation을 만들고, 이를 기준으로 물체가 있을법한 박스를 추론합니다.

하지만 R-CNN 이후 Region Proposal 과정 역시 뉴럴 네트워크가 수행하도록 발전하였습니다.
때문에 더 이상 사용되어지지 않는 알고리즘이므로 이 정도만 알고 넘어가도록 하겠습니다.
더 자세한 내용이 궁금하시다면 다음의 자료를 참고하시면 좋습니다. [4]
2. Feature Extraction
Selective Search를 통해서 찾아낸 2천개의 박스 영역은 227 x 227 크기로 리사이즈 됩니다. (warp)
그리고 Image Classification으로 미리 학습되어 있는 CNN 모델을 통과하여 4096 크기의 특징 벡터를 추출합니다.
이 때, 미리 학습된 모델이 구체적으로 어떤 것을 의미하는지 살펴보겠습니다.
저자들은 이미지넷 데이터(ILSVRC2012 classification)로 미리 학습된 CNN 모델을 가져온 다음, fine tune하는 방식을 취했습니다.
fine tune 시에는 실제 Object Detection을 적용할 데이터 셋에서 ground truth에 해당하는 이미지들을 가져와 학습시켰습니다.
그리고 Classification의 마지막 레이어를 Object Detection의 클래스 수 N과 아무 물체도 없는 배경까지 포함한 N+1로 맞춰주었습니다.
fine tune을 적용했을 떄와 하지 않았을 때의 성능을 비교해보면 아래와 같습니다.

FT는 fine tune의 약자이며, 각 CNN 레이어 층에서 추출된 벡터로 SVM Classifier를 학습시켜서 얻은 mAP를 비교한 것입니다.
mAP는 Object Detection 분야에서 많이 사용되는 정확도 측정 지표인데, 더 궁금하신 분들은 다음의 포스팅을 참고하면 좋습니다. [3]
전반적으로 fine tuning을 거친 것들이 성능이 더 좋음을 확인할 수 있습니다.
그리고 마지막에 BB로 적힌 것은 Bounding Box Regression을 적용한 것인데, 해당 내용은 아래에 더 자세히 이어집니다.
정리하자면, 미리 이미지 넷으로 학습된 CNN을 가져와서, Object Detection용 데이터 셋으로 fine tuning 한 뒤,
selective search 결과로 뽑힌 이미지들로부터 특징 벡터를 추출합니다.
3. Classification
CNN을 통해 추출한 벡터를 가지고 각각의 클래스 별로 SVM Classifier를 학습시킵니다.
주어진 벡터를 놓고 이것이 해당 물체가 맞는지 아닌지를 구분하는 Classifier 모델을 학습시키는 것입니다.
이미 학습되어 있는 CNN Classifier를 두고 왜 SVM을 별도로 학습시키는 것일까요?
이 부분에 대해서는 저자들의 답변은 이렇습니다.
"그냥 CNN Classifier를 쓰는 것이 SVM을 썼을 때보다 mAP 성능이 4% 정도 낮아졌다.
이는 아마도 fine tuning 과정에서 물체의 위치 정보가 유실되고 무작위로 추출된 샘플을 학습하여 발생한 것으로 보인다."
썩 그렇게 명확한 것은 아니지만 SVM을 붙여서 학습시키는 기법 역시 더 이상 사용되지 않으므로 이 정도로 넘어가겠습니다.
더 궁금하신 분들은 원본 논문[1]의 Appendix B를 살펴보시면 됩니다.
4. Non-Maximum Suppression
SVM을 통과하여 이제 각각의 박스들은 어떤 물체일 확률 값 (Score) 값을 가지게 되었습니다.
그런데 2천개 박스가 모두 필요한 것일까요?
동일한 물체에 여러 개의 박스가 쳐져있는 것이라면, 가장 스코어가 높은 박스만 남기고 나머지는 제거해야합니다.
이 과정을 Non-Maximum Supperssion이라 합니다.

서로 다른 두 박스가 동일한 물체에 쳐져 있다고 어떻게 판별할 수 있을까요?
여기서 IoU (Intersection over Union) 개념이 적용됩니다.
쉽게 말하면 두 박스의 교집합을 합집합으로 나눠준 값입니다.
두 박스가 일치할 수록 1에 가까운 값이 나오게 됩니다.
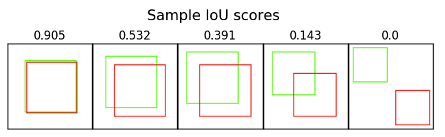
논문에서는 IoU가 0.5 보다 크면 동일한 물체를 대상으로 한 박스로 판단하고 Non-Maximum Suppression을 적용합니다.
5. Bounding Box Regression
지금까지 물체가 있을 법한 위치를 찾았고, 해당 물체의 종류를 판별할 수 있는 클래시피케이션 모델을 학습시켰습니다.
하지만 Selective Search를 통해서 찾은 박스 위치는 상당히 부정확합니다.
따라서 성능을 끌어올리기 위해서 이 박스 위치를 교정해주는 부분을 Bounding Box Regression이라 합니다.
먼저 하나의 박스를 다음과 같이 표기할 수 있습니다.
여기서 x, y는 이미지의 중심점, w, h는 각각 너비와 높이입니다.

Ground Truth에 해당하는 박스도 다음과 같이 표기할 수 있습니다.

우리의 목표는 P에 해당하는 박스를 최대한 G에 가깝도록 이동시키는 함수를 학습시키는 것입니다.
박스가 인풋으로 들어왔을 때, x, y, w, h를 각각 이동 시켜주는 함수들을 표현해보면 다음과 같습니다.

이 때, x, y는 점이기 때문에 이미지의 크기에 상관없이 위치만 이동시켜주면 됩니다.
반면에 너비와 높이는 이미지의 크기에 비례하여 조정을 시켜주어야 합니다.
이러한 특성을 반영하여 P를 이동시키는 함수의 식을 짜보면 다음과 같습니다.

우리가 학습을 통해서 얻고자 하는 함수는 저 d 함수입니다.
저자들은 이 d 함수를 구하기 위해서 앞서 CNN을 통과할 때 pool5 레이어에서 얻어낸 특징 벡터를 사용합니다.
그리고 함수에 학습 가능한 웨이트 벡터를 주어 계산합니다.
이를 식으로 나타내면 아래와 같습니다.
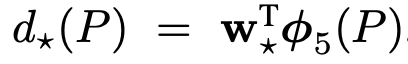
이제 웨이트를 학습시킬 로스 펑션을 세워보면 다음과 같습니다.
일반적인 MSE 에러 함수에 L2 normalization을 추가한 형태입니다.
저자들은 람다를 1000으로 설정하였습니다.

여기서 t는 P를 G로 이동시키기 위해서 필요한 이동량을 의미하며 식으로 나타내면 아래와 같습니다.
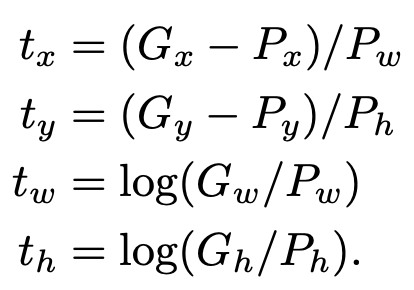
정리를 해보면 CNN을 통과하여 추출된 벡터와 x, y, w, h를 조정하는 함수의 웨이트를 곱해서
바운딩 박스를 조정해주는 선형 회귀를 학습시키는 것입니다.
R-CNN에서 학습이 일어나는 부분
1. 이미지 넷으로 이미 학습된 모델을 가져와 fine tuning 하는 부분
2. SVM Classifier를 학습시키는 부분
3. Bounding Box Regression
속도 및 정확도
테스트 시에 R-CNN은 이미지 하나 당 GPU에서는 13초, CPU에서 54초가 걸린다고 합니다.
속도 저하의 가장 큰 병목 구간은 selective search를 통해서 찾은 2천개의 영역에 모두 CNN inference를 진행하기 때문입니다.
정확도의 경우 Pascal VOC 2010을 기준으로 53.7%를 기록하였습니다.
이는 당시 기존의 기록들을 모두 갈아치우며 획기적으로 Object Detection 분야에 발전을 이끌었던 스코어입니다.
마치며
지금까지 딥 러닝을 이용한 Object Detection의 포문을 연 R-CNN을 살펴보았습니다.
초기 모델이라서 그런지 전통적인 비전 알고리즘들도 함께 사용하여 구조가 상당히 복잡한 것을 알 수 있습니다.
하지만 저자들은 이를 기점으로 Fast R-CNN, Faster R-CNN과 같이 속도와 정확도 모두 개선시킨 모델들을 내놓았습니다.
이들 논문들도 차례로 리뷰할 예정입니다.
끝으로 질문이 있으시거나 잘못된 내용이 있다면 댓글 남겨주시면 감사하겠습니다.
Reference
[1] Ross et al, Rich feature hierarchies for accurate object detection and semantic segmentation, 2014
[2] Lunit, R-CNNs Tutorial, https://blog.lunit.io/2017/06/01/r-cnns-tutorial/
[3] mAP 개념, https://better-today.tistory.com/3
[4] standford 231b, selective search, http://vision.stanford.edu/teaching/cs231b_spring1415/slides/ssearch_schuyler.pdf
Q&A 추가
댓글로 달린 질문에 대한 답을 추가합니다. 결론부터 말씀드리면 원문을 보아 w*는 벡터이고, 이를 선형 회귀로 학습시킨다 정도가 될 것 같습니다. 먼저 원문을 보면 다음과 같습니다.

질문의 요지는 벡터 w만을 학습시키는 것이 bounding box regression에 충분한가? 과연 선형 회귀 만으로 가능한 것인가? 였습니다. 먼저 w*의 차원을 한 번 살펴보겠습니다. φ(Pi)는 VGG넷의 pool5를 거친 피쳐맵으로, 원래의 VGG에서는 이를 쫙 펴서 4096 차원의 벡터로 만든 다음 FC에 넘겨줍니다. 즉, φ(Pi)를 4096 차원 벡터라고 보면 w*역시 4096 차원 벡터인 것을 알 수 있습니다.
그렇다면 피쳐 맵과 w*를 곱해주어서 나오는 결과값의 범위를 알아보겠습니다. 결국 이 둘을 곱해서 구하고 싶은 값은 x, y, w, h로 이는 모두 0에서 1 사이의 값입니다. (각각을 바운딩 박스의 너비와 높이로 나누어 주므로) 즉, 0과 1 사이의 바운딩 박스 조정 값을 구하기 위해서 4096 차원의 벡터를 학습시키는 것입니다. 직접 R-CNN을 구현해보지 못하여 확답을 내릴 수 는 없지만, 그다지 피쳐 벡터가 부족하다는 느낌이 들지는 않습니다.
마지막으로 R-CNN 이후 Bounding Box Regression 접근들에 대해서 알아보겠습니다. 아래 그림은 저자들의 후속 논문인 Faster R-CNN에서 Bounding Box Regression이 진행되는 부분입니다.
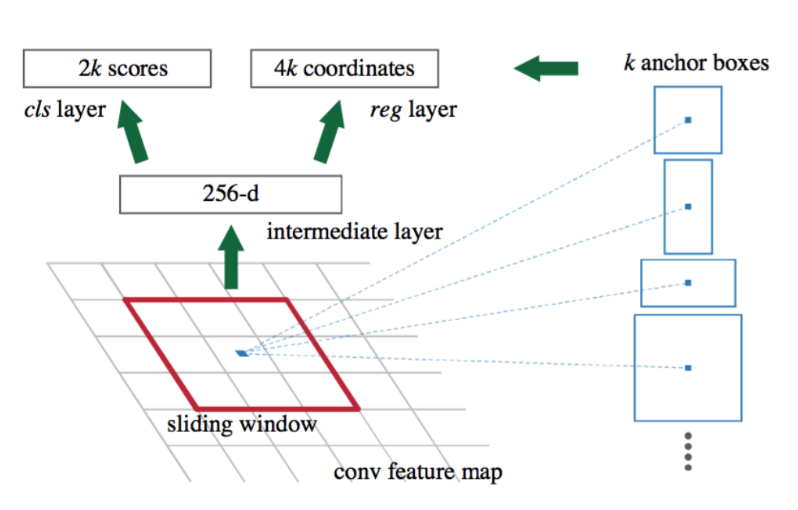
위 그림에서 reg layer로 표시된 부분이 Bounding Box Regression을 담당하는 레이어로 1x1 컨볼루션으로 간단히 구성되어 있습니다. 이러한 후속 아키텍쳐들을 보더라도 바운딩 박스 리그레션에 많은 파라미터를 할애하지 않고도 더 좋은 성능을 내는 것을 볼 수 있습니다. 이러한 내용들로 미루어 볼 때, 선형 회귀만으로도 충분히 바운딩 박스 리그레션을 구현할 수 있지 않을까요?
이상으로 질문에 대한 제 부연 설명입니다. 다만, 직접 구현해보기 전까지 확신할 수 없다고 생각하며, 질문 주신 분의 의견에 많이 공감합니다. 조만간 구현에 관한 포스팅도 올릴 예정인데 직접 실험해보면서 말씀해주신 부분들을 검증해보도록 하겠습니다 ㅎㅎ
질문 주셔서 감사하고 앞으로도 많은 관심 부탁드립니다.
'갈아먹는 머신러닝 시리즈 > 컴퓨터 비전' 카테고리의 다른 글
| 갈아먹는 Semantic Segmentation [1] Fully Convolutional Network (0) | 2020.01.09 |
|---|---|
| 갈아먹는 Object Detection [4] Faster R-CNN (8) | 2020.01.07 |
| 갈아먹는 Face Detection [1] MTCNN (3) | 2020.01.06 |
| 갈아먹는 Object Detection [3] Fast R-CNN (8) | 2020.01.05 |
| 갈아먹는 Object Detection [2] Spatial Pyramid Pooling Network (7) | 2020.01.04 |